Transformation of Data¶
In [2]:
library(tidyverse)
library(nycflights13)
library(gridExtra)
5. Data Transformation¶
5.1.3 dplyr basics¶
In this chapter you are going to learn the five key dplyr functions that allow you to solve the vast majority of your data manipulation challenges:¶
- Pick observations by their values (filter()).
- Reorder the rows (arrange()).
- Pick variables by their names (select()).
- Create new variables with functions of existing variables (mutate()).
- Collapse many values down to a single summary (summarise()).
In [3]:
head(flights) # 2013년 nyc에 이착률 비행기.
5.2 Filter rows with filter()¶
- data.table을 데이터 규모가 큰 경우 dplyr보단 더 많이 사용하지만 불편하다.
In [4]:
filter(flights, month==1, day==1) %>% head(2)
In [5]:
flights %>% filter(month==1,day==1) %>% head(2)
Logical Operations¶
- | vs || (or)
In [6]:
c(1,2,3) > 2
In [7]:
c(1,2,3) > 2 | c(4,5,6) <= 4 # 짝을 지어서 한다. 순서대로 1>2,4<=4 이런식으로 짝을 지어서
In [8]:
c(1,2,3) > 2 || c(4,5,6) <= 4 # 맨앞에꺼 하나만 가지고 한다.
In [9]:
filter(flights, month==11 | month==12) %>% head(2)
- %in% 연산자 : 포함하는 것
In [10]:
filter(flights, month %in% c(11,12)) %>% head(2) # 중의 연산자 : month가 11월 12월 중.
5.2.3 Na Missing Value¶
In [11]:
is.na(NA)
In [12]:
!is.na("123")
In [13]:
NA ^ 0 # -> 1 모든 수의 0 승은 1
NA | TRUE
FALSE & NA
- But...
In [14]:
## but
NA * 0 #NA....?
5.2.4 Exercises¶
1. Find all flights that
1.1. Had an arrival delay of two or more hoursIn [15]:
filter(flights, arr_delay>=120) %>% head(2)
1.2. Flew to Houston (IAH or HOU)In [16]:
filter(flights, dest %in% c('IAH','HOU')) %>% head(2)
1.3. Were operated by United, American, or DeltaIn [17]:
unique(flights$carrier)
In [18]:
filter(flights, carrier %in% c('UA','AA','DL')) %>% head(2)
1.4. Departed in summer (July, August, and September)In [19]:
filter(flights, month %in% 7:9) %>% head(2)
In [20]:
filter(flights, between(month,7,9)) %>% head(2)
1.5. Arrived more than two hours late, but didn’t leave lateIn [21]:
filter(flights, dep_delay<=0, arr_delay > 120) %>% head(2)
1.6. Were delayed by at least an hour, but made up over 30 minutes in flightIn [22]:
filter(flights, dep_delay >= 60, arr_delay < dep_delay - 30) %>% head(2)
1.7. Departed between midnight and 6am (inclusive)In [23]:
filter(flights, dep_time <= 600) %>% head(2)
3. How many flights have a missing dep_time? What other variables are missing? What might these rows represent?In [24]:
filter(flights,is.na(dep_time)) %>% head(2)
5.3 Arrange¶
In [25]:
arrange(flights, arr_delay) %>% head(2)# 오름 차순
In [26]:
arrange(flights, desc(arr_delay)) %>% head(2) #내림 차순
5.4 Select¶
In [27]:
select(flights, year, month,day) %>% head(2)
In [28]:
select(flights, year:day) %>% head(2)
In [29]:
select(flights, -(year:day)) %>% head(2)
starts_with("abc"): matches names that begin with “abc”.¶
In [30]:
select(flights, starts_with('dep')) %>% head(2)
ends_with("xyz"): matches names that end with “xyz”.¶
In [31]:
select(flights, ends_with('delay')) %>% head(2)
Starts with & End with¶
In [32]:
select(flights, ends_with('delay'),starts_with('dep')) %>% head(2)
contains("ijk"): matches names that contain “ijk”.¶
In [33]:
select(flights, contains('d')) %>% head(3)
matches("(.)\1")¶
- selects variables that match a regular expression.
This one matches any variables that contain repeated characters. You’ll learn more about regular expressions in strings. - Regular Expression.
In [34]:
select(flights, matches('d[aeiou]')) %>% head(2) # d뒤에 aeiou가 붙는 경우
num_range("x", 1:3) matches x1, x2 and x3. 동일한 변수 뒤에 숫자가 붙은 경우¶
Rename : Change Colnum's Name¶
In [35]:
rename(flights, tail_num = tailnum) %>% head(2)
Everything : 모든 Column's Names¶
- Column의 순서를 변경할 때 사용.
In [36]:
select(flights, time_hour, air_time, everything()) %>% head(2)
5.5 Add New variables with mutate()¶
In [37]:
flights_sml <- select(flights,
year:day,
ends_with("delay"),
distance,
air_time
)
In [38]:
mutate(flights_sml, gain=arr_delay - dep_delay, speed = distance / air_time * 60) %>% head(2)
pipe¶
In [39]:
arrange(filter(flights,month==1),day) %>% head(2)
- 위 식을 보기 편하게 변경.
In [40]:
flights %>% filter(month==1) %>% arrange(day) %>% head(2)
Summarize¶
In [41]:
summarise(flights, delay=mean(dep_delay,na.rm=T))
In [42]:
by_day <- flights %>% group_by(year,month,day) %>% summarise(delay=mean(dep_delay,na.rm=T))
head(by_day)
In [43]:
flights %>% group_by(year,month,day) %>% summarise(delay=mean(dep_delay,na.rm=T), cnt=n()) %>% head(2)
5. 탐색적 모형 분석¶
- 모형이 있는 것이 아니라, 그냥 데이터를 뒤져보는 것을 말한다.
- 환인적 탐색 분석보다 탐색적 모형분석이 오래 걸린다.
- 그래프를 그려본다. (특징을 슥 찾아본다.)
In [44]:
options(repr.plot.height=3)
ggplot(data=diamonds) + geom_histogram(aes(x=carat))

- 특이한 패턴이 나온다. 특정한 무게에서 짤라서 쓰지 않을까?
In [45]:
ggplot(data=diamonds) + geom_histogram(aes(x=carat), binwidth = 0.01)

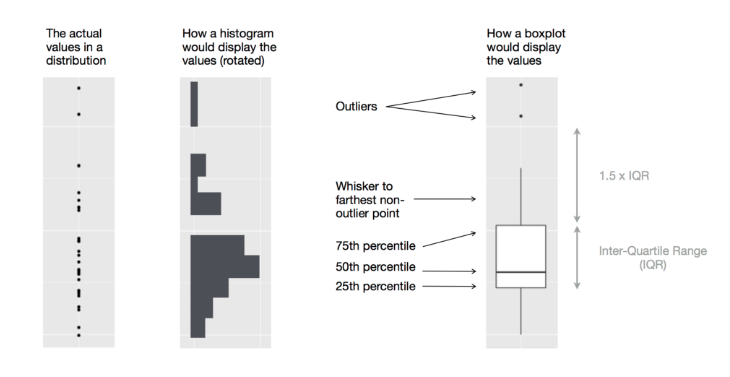
기술적으로 대단한 것은 아니지만, 발상이 대단한 부분이다.¶
- 양봉 그래프의 경우 boxplot을 그리게 되면 중간의 데이터가 있던 없던 동일한 모양이 나오는데
- Histogram을 세로로 세운다면 정보의 손실이 없다.
In [46]:
ggplot(data = mpg, mapping = aes(x = class, y = hwy)) +
geom_boxplot()

In [69]:
ggplot(data = mpg) +
geom_boxplot(mapping = aes(x = reorder(class, hwy, FUN = median), y = hwy)) # reorder median을 기준으로

In [47]:
diamonds %>%
count(color, cut) %>%
ggplot(mapping = aes(x = color, y = cut)) +
geom_tile(mapping = aes(fill = n))

7.5.3 Two continuous variables¶
In [48]:
ggplot(data = diamonds) +
geom_point(mapping = aes(x = carat, y = price))

In [49]:
ggplot(data = diamonds) +
geom_point(mapping = aes(x = carat, y = price), alpha = 1 / 100)

- geom_bin2d() and geom_hex() divide the coordinate plane into 2d bins and then use a fill color to display how many points fall into each bin.
In [50]:
library(hexbin)
In [51]:
gg1 <- ggplot(data = diamonds) +
geom_bin2d(mapping = aes(x = carat, y = price))
# install.packages("hexbin")
gg2 <- ggplot(data = diamonds) +
geom_hex(mapping = aes(x = carat, y = price))
grid.arrange(gg1,gg2,ncol=2)

- Another option is to bin one continuous variable so it acts like a categorical variable.
In [52]:
ggplot(data = diamonds, mapping = aes(x = carat, y = price)) +
geom_boxplot(mapping = aes(group = cut_width(carat, 0.1)))

Boxplot Outlier Text Label¶
In [53]:
options(repr.plot.height=4)
ggplot(mpg,aes(class,hwy)) +
geom_boxplot(outlier.alpha = 0) + # Ouliter 가 보기 힘들다(점과 겹쳐서) outlier.alpha = 0 하면 그림을 없애준다.
geom_text(aes(label=rownames(mpg)))

Only Text on Outliers¶
In [54]:
ggplot(mpg,aes(class,hwy)) + geom_boxplot() # <- 활용

In [55]:
q1 = quantile(mpg$hwy,.25)
q3 = quantile(mpg$hwy,.75)
iqr = q3 - q1
upper = q3 + 1.5 * iqr
lower = q1 - 1.5 * iqr
In [56]:
filter(mpg, hwy>upper | hwy < lower)
- 각각의 Class에 적용하기 귀찮다. 함수로 만든다.
In [57]:
filter.Outlier <- function(df){
q1 = quantile(df$hwy,.25)
q3 = quantile(df$hwy,.75)
iqr = q3 - q1
upper = q3 + 1.5 * iqr
lower = q1 - 1.5 * iqr
df %>% filter(hwy < lower | hwy > upper)
# R에서는 Return을 안하면 마지막행이 Return 된다.
}
In [58]:
mpg <- mpg %>% mutate(name=row_number())
In [59]:
mpg %>% filter.Outlier()
dplyr 의 do function¶
- do function : group 별로 적용되는 함수 또는 행위 적용
- 원리 : group_by 로 짤랐던 df를 각각에 함수를 적용하고 그결과를 rbind 한다고 생각하면 된다.
- input data 에는 Dataframe이다.
- dataframe이 들어갈 자리에 . 을 사용.
In [60]:
mpg %>% group_by(class) %>% do(head(.,1)) # 그룹바이한 class에 대해 각 df가 만들어지고 그게 .자리에 들어간다.
In [61]:
mpg %>% group_by(class) %>%
do(filter.Outlier((.)))
# do -> 그룹별로 함수 적용
# (짤라냈던 각각의 df를 . 자리가 각각 넣어서 한다. 그리고 결과를 합친다.)
- name자리에 새로운 Column 명을 한다면 해당 부분이 Label이 된다.
In [62]:
x = mpg %>% group_by(class) %>% do(filter.Outlier(.))
ggplot(mpg, aes(class,hwy)) + geom_boxplot(outlier.alpha = 0) +
geom_text(data=x,aes(label=name))

2. 연비 top3¶
In [63]:
filter.hwy <- function(df){
df %>% arrange(desc(hwy)) %>% head(3)
}
mpg %>% group_by(model) %>% do(filter.hwy(.))
In [64]:
mpg %>% group_by(model) %>% do((.) %>% arrange(desc(hwy)) %>% head(3)) # do((.)) do안에서 사용하려면 (.) 로 묶어줘야된다.
Tips¶
- rbind, cbind 보다 빠른 함수 : bind_rows,bind_cols 사용법은 동일하다.
filtering 후 차이를 알고 싶을때¶
- setdiff() 함수 활용
In [65]:
flights <- flights %>% mutate(name= row_number())
aa <- filter(flights, carrier == 'AA')
july <- filter(flights, month == 7)
i = setdiff(aa$name,july$name)
In [66]:
head(flights[i,])