3.Model & ETC¶
In [17]:
library(plot3Drgl)
library(nycflights13)
In [18]:
options(repr.plot.height=3)
points3D(iris$Sepal.Length,iris$Sepal.Width,iris$Petal.Length)

In [19]:
scatter3Drgl(iris$Sepal.Length,iris$Sepal.Width,iris$Petal.Length)
Date - time¶
In [20]:
library(tidyverse)
library(forcats)
library(lubridate)
In [21]:
month_levels <- c(
"Jan", "Feb", "Mar", "Apr", "May", "Jun",
"Jul", "Aug", "Sep", "Oct", "Nov", "Dec"
)
x1 <- c("Dec", "Apr", "Jan", "Mar")
x2 <- c("Dec", "Apr", "Jam", "Mar")
y1 <- factor(x1, levels = month_levels)
In [22]:
y1
In [23]:
ymd_hms("2017-01-31 20:11:59")
In [24]:
flights %>% select(year,month,day,hour, minute) %>%
mutate(departure = make_datetime(year,month,day,hour,minute)) %>% head(3)
In [25]:
make_datetime_100 <- function(year, month, day, time) {
make_datetime(year, month, day, time %/% 100, time %% 100) # %/% 몫, %%나머지
}
In [26]:
flights_dt <- flights %>%
filter(!is.na(dep_time), !is.na(arr_time)) %>%
mutate(
dep_time = make_datetime_100(year, month, day, dep_time),
arr_time = make_datetime_100(year, month, day, arr_time),
sched_dep_time = make_datetime_100(year, month, day, sched_dep_time),
sched_arr_time = make_datetime_100(year, month, day, sched_arr_time)
) %>%
select(origin, dest, ends_with("delay"), ends_with("time"))
In [27]:
head(flights_dt)
In [28]:
flights_dt %>%
ggplot(aes(dep_time)) +
geom_freqpoly(binwidth = 86400) # 86400 seconds = 1 day

- histogram을 하게 된다면 보기가 어렵다 그래서 사용하는게 freqploy
In [29]:
flights_dt %>%
ggplot(aes(dep_time)) +
geom_histogram(binwidth = 86400) # 86400 seconds = 1 day 보기 어렵다. 너무 백빽함.

In [30]:
flights_dt %>%
filter(dep_time < ymd(20130102)) %>% # filter 날짜.
ggplot(aes(dep_time)) +
geom_freqpoly(binwidth = 600) # 600 s = 10 minutes

In [31]:
datetime <- today()
In [38]:
year(datetime)
month(datetime)
mday(datetime)
yday(datetime)
wday(datetime)
wday(datetime, label = TRUE, abbr = FALSE)
In [37]:
data.frame(year=year(datetime),mon = month(datetime),mday = mday(datetime),yday = yday(datetime),wday = wday(datetime),wday_label = wday(datetime, label = TRUE, abbr = FALSE))
In [39]:
flights_dt %>%
mutate(wday = wday(dep_time, label = TRUE)) %>% # 요일별 Count
ggplot(aes(x = wday)) +
geom_bar()

In [40]:
flights_dt %>%
mutate(minute = minute(dep_time)) %>%
group_by(minute) %>%
summarise( avg_delay = mean(arr_delay, na.rm = TRUE),n = n()) %>%
ggplot(aes(minute, avg_delay)) + geom_line()

In [41]:
flights_dt %>%
count(week = floor_date(dep_time, "week")) %>%
ggplot(aes(week, n)) +
geom_line()

4. MODEL¶
In [44]:
library(modelr)
In [43]:
head(sim1) # 예제 데이터.
In [45]:
ggplot(sim1) +geom_point(aes(x,y))

- r + uni form => 형태가 같은 1개의 숫자.
In [46]:
models <- tibble(
a1 = runif(250, -20, 40), # 난수를 생성, 250개를 -20~40까지. runif 일정구간에서 나올 확률이 동일.
a2 = runif(250, -5, 5)
)
In [47]:
head(models)
In [48]:
ggplot(sim1, aes(x,y)) +
geom_abline(aes(intercept=a1, slope=a2),data=models, alpha =.25) + # abline은 절편과 기울기를 주면 해당 그림을 그린다.
geom_point()

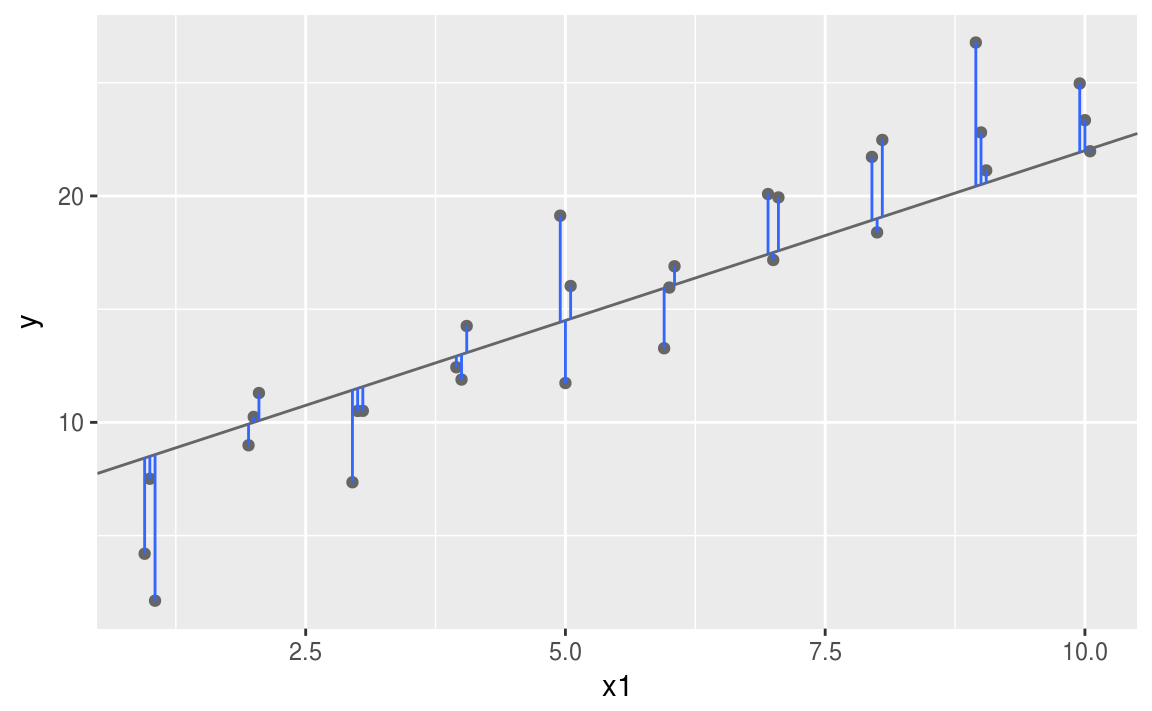
회귀식¶
- SSE = sum of square error 1/n * sse = MSE (mean of Square Erros) => var (분산)
In [49]:
model1 <- function(a, data) {
a[1] + data$x * a[2]
}
In [50]:
model1(c(7, 1.5), sim1)
In [51]:
measure_distance <- function(mod, data) {
diff <- data$y - model1(mod, data)
sqrt(mean(diff ^ 2))
}
RMSE => Route Mean of Square Errors = SD¶
In [52]:
measure_distance(c(7,1.5), sim1) # RMSE => Route Mean of Square Errors = SD
# 절편 : 7, 기울기:1.5
In [53]:
measure_distance(c(mean(sim1$y),0), sim1) # 표준편차
In [54]:
sd(sim1$y)
In [55]:
sim1_dist <- function(a1, a2) {
measure_distance(c(a1, a2), sim1)
}
In [56]:
map_dbl(c(1,2,3),sqrt) # 각각에 적요해서 Vector로 출력
In [57]:
map2_dbl(c(1,2,3),c(4,5,6),function(x,y){x+y}) #인자를 2개를 받는다. 짝을 지어서
In [58]:
models <- models %>%
mutate(dist = purrr::map2_dbl(a1, a2, sim1_dist))
In [59]:
head(models)
In [60]:
ggplot(sim1, aes(x, y)) +
geom_point(size = 2, colour = "grey30") +
geom_abline(
aes(intercept = a1, slope = a2, colour = -dist), # 거리가 가까울수록 연한 그래프
data = filter(models, rank(dist) <= 10)
)

- 위와 동일한 방법
In [61]:
ggplot(sim1, aes(x, y)) +
geom_point(size = 2, colour = "grey30") +
geom_abline(
aes(intercept = a1, slope = a2, colour = -dist),
data = models %>% arrange(dist) %>% head(10)
)

In [63]:
ggplot(models) +
geom_point(aes(a1,a2, color = -dist)) # 색이 연할 수록 거리가 가깝다. 즉, 그래프가 그쪽으로 간다.

나만의 모델을 만들기 위해서는 optim을 사용하면 된다.¶
- 원해는 내용을 measure_distance에 다른 함수를 만들어 내면된다.
In [65]:
best <- optim(c(0,0), measure_distance,data=sim1) # c(0,0) :Initial values for the parameters to be optimized over.
best$par
In [66]:
ggplot(sim1, aes(x, y)) +
geom_point(size = 2, colour = "grey30") +
geom_abline(intercept = best$par[1], slope = best$par[2]) # 기울기가 best$par[2] 절편 : best$par[1]

In [67]:
lm(y~x, sim1)
In [68]:
names(diamonds)
model <- lm(price ~ carat, diamonds)
In [69]:
summary(model)
- Multiple R-squared: 0.8493 이 모형이 전체를 84% 설명한다.
- 전체분산 - 해당식의 분산 / 전체분산 = 84%
- 해당 식의 분산은 16% (전체 비중)
회귀식에서 많이 쓰늑네 절편을 고정시키는 것이다.¶
- diamonds가 아주 작다고 하면 -2256 이면 돈을 받아야 한다. 말이 안된다. 해석이 말이 안됨.
In [70]:
lm(price ~ 0 + carat, diamonds) %>% summary() # intercept 가 사라진다. / 절편 생략.
In [71]:
lm(price ~ carat + z, diamonds) %>% summary() # 케럿이 커지면서 z가 줄어야된다.
선형적인 모양이 아니다. 확 올라가는 모양이다.¶
- 제곱을 사용해본다
In [72]:
ggplot(diamonds) + geom_point(aes(carat,price), alpha=.02)

In [73]:
lm(price ~ carat ^2, diamonds) %>% summary() # 적용이 안된다.
- I() 함수 적용.
In [74]:
lm(price ~ I(carat^2) + carat + z, diamonds) %>% summary() # I()를 사용하게 된다면 적용된다.
상호작용.¶
- Carat^2 가 안되는 이유
- lm에서 곱하기는 상호작용을 의미한다. carat^2 = carat * carat, 두개의 변수의 곱이 미치는 영향을 의미한다.
- 곱을 표현하고 싶다면 변수:변수 로 표현한다.
- 상호작용 항이라고 한다. a,b의 상호작으로 보게 되면 a,b도 같이 들어간다, a + b + a:b 이런식으로 #### a + b + a:b => a*b가 된다.
In [75]:
lm(price ~ carat + z + carat:z, diamonds) %>% summary() # 다변량 시간에 배운것 같다. 이제 이해가간다. 다시 보자
In [77]:
lm(price ~ carat * z, diamonds) %>% summary()
상호작용 2¶
- 소득, 성적
- 소득이 높다면 성적이 높다. 하지만 학교가 교육프로그램이 좋다면 소득이높다고 하더라도 성적이 완만하게 올라가는 경향이 있다고 치자.
소득이 성적에 미치는 영향을 학교가 조절해준다. 이러한 조절을 moderation이라고 한다.
- 소득이 높다면 성적이 높다. 하지만 학교가 교육프로그램이 좋다면 소득이높다고 하더라도 성적이 완만하게 올라가는 경향이 있다고 치자.
- 성적 ~ 소득 + 학교의영향:소득
- 성적 ~ a*소득 + b(학교의영향:소득) => (a+b학교영향):소득
- 성적은 a+b학교영향에 따라서 기울기가 달라진다. 즉, 학교의 영향에 따라서 기울기가 달라진다.
상호작용을 언제 판단하고 적용해보는가?¶
- 이론적 배경지식을 활용한다.
- 모든 상호작용을 다 집어넣고 lasso를 하게 된다면 컴퓨터가 통계적으로 판단해서 상호작용이 없을 경우 0 으로 바꿔버린다.