QVC Analysis (E-Commerce 판매 데이터 분석)¶
- 전처리 과정은 Jupyter 메모리상 중간에 되지를 않게 되어 .R 내용을 확인
- Data_Handling
- Making OrderData
- Clustering
- Recommand System
필요한 파일.¶
- Customer master2.csv
- order_data.csv
- product.csv
- timezone.csv
- zipcode.csv
- Product airtime.csv
- pre_order_data.csv
- *.txt 파일
In [46]:
library(stringr)
library(arules)
library(dplyr)
library(maps)
library(ggplot2)
library(ggmap)
library(gridExtra)
library(reshape2)
library(arulesSequences)
library(lubridate)
In [2]:
theme_set(theme_gray(base_size = 13))
Data Load¶
In [3]:
customer <- read.csv("data/Customer master2.csv")
customer$SHOPPER_SEGMENT_CODE <- as.factor(customer$SHOPPER_SEGMENT_CODE)
In [4]:
head(customer)
In [83]:
order_df <- read.csv("data/order_data.csv", stringsAsFactors = F)
order_df$SHOPPER_SEGMENT_CODE[is.na(order_df$SHOPPER_SEGMENT_CODE)] <- 0
order_df$SHOPPER_SEGMENT_CODE <- as.factor(order_df$SHOPPER_SEGMENT_CODE)
In [6]:
product <- read.csv("data/Product master2.csv", stringsAsFactor = F)
In [7]:
zip <- read.csv("data/zipcode.csv", stringsAsFactors = F)
Data 확인.¶
1. 고객 분포도. Zip Code 별 고객 분포도.¶
In [8]:
v_customer <- customer %>% group_by(ZIP_CODE) %>% summarize(cnt = n()) %>% filter(cnt > 5)
v_customer <- merge(v_customer,zip[,c(1,3:5)],by.x="ZIP_CODE",by.y="zip")
In [9]:
head(v_customer)
지도 그리기¶
In [10]:
options(repr.plot.width=5, repr.plot.height=5)
In [11]:
map<-get_map(location='united states', zoom=4, maptype = "terrain",
source='google',color='color')
ggmap(map) + geom_point(
aes(x=longitude, y=latitude, show_guide = TRUE, colour=cnt, size=cnt),
data=v_customer, alpha=1,na.rm = T) +
scale_color_gradient(low="beige", high="blue")

지도그리기 2¶
In [12]:
options(repr.plot.width=5, repr.plot.height=3)
In [13]:
us <- map_data("state")
city <- customer %>% group_by(city) %>% summarize(cnt = n())
city <- city %>% mutate(avg = cnt/mean(cnt))
city$city <- tolower(city$city)
gg <- ggplot()
gg <- gg + geom_map(data=us, map=us,
aes(x=long, y=lat, map_id=region),
fill="#ffffff", color="#ffffff", size=0.25)
gg <- gg + geom_map(data=city, map=us,
aes(fill=cnt, map_id=city),
color="#ffffff", size=0.25)
gg <- gg + scale_fill_continuous(low='thistle2', high='darkred',
guide='colorbar')
gg <- gg + labs(x=NULL, y=NULL)
gg <- gg + coord_map("albers", lat0 = 39, lat1 = 45)
gg <- gg + theme(panel.border = element_blank())
gg <- gg + theme(panel.background = element_blank())
gg <- gg + theme(axis.ticks = element_blank())
gg <- gg + theme(axis.text = element_blank())
gg

timezone 별 고객 분포도¶
In [14]:
options(repr.plot.width=7, repr.plot.height=3)
In [15]:
timezone_customer <- customer %>% group_by(timezone) %>% summarize(cnt=n())
ggplot(timezone_customer,aes(x=timezone,y=cnt,fill=timezone)) + geom_bar(stat="identity")

2. State 별 고객 분포¶
In [16]:
state_number <- v_customer %>% group_by(state) %>% summarize(cnt = sum(cnt)) %>% arrange(desc(cnt))
ggplot(v_customer, aes(x=state,y=cnt)) + geom_bar(stat="identity") + theme(axis.text.x = element_text(angle = 90, hjust = 1))

3. State 별 Segment 별 고객 분포¶
In [17]:
customer$SHOPPER_SEGMENT_CODE[is.na(customer$SHOPPER_SEGMENT_CODE)] <- 0
customer$SHOPPER_SEGMENT_CODE <- factor(customer$SHOPPER_SEGMENT_CODE)
seg_customer <- customer
In [18]:
names(seg_customer)[4] <- "CODE"
In [19]:
ggplot(seg_customer,aes(x=STATE,fill=CODE)) + geom_bar() + theme(axis.text.x = element_text(angle = 90, hjust = 1))

4. segment 별 고객 분포¶
In [20]:
segment_customer <- customer %>% group_by(SHOPPER_SEGMENT_CODE) %>% summarize(cu_cnt = n()) %>% mutate(prob = round((cu_cnt/sum(cu_cnt)),2)*100)
segment_customer$SHOPPER_SEGMENT_CODE[is.na(segment_customer$SHOPPER_SEGMENT_CODE)] <- 0
In [21]:
bp<- ggplot(segment_customer, aes(x="", y=cu_cnt, fill=as.factor(SHOPPER_SEGMENT_CODE)))+
geom_bar(width = 1, stat = "identity")
pie <- bp + coord_polar("y", start=0)
# scale_fill_brewer("Blues") + blank_theme +
pie +
#theme(axis.text.x=element_blank())+
geom_text(aes(y = cu_cnt/3 + c(0, cumsum(cu_cnt)[-length(cu_cnt)]),
label = paste0(SHOPPER_SEGMENT_CODE,":",prob,"%")), size=3)

5. segment 별 구매 횟수¶
In [22]:
segment_order <- order_df %>% group_by(SHOPPER_SEGMENT_CODE) %>% summarize(or_cnt=n())
segment_order$percent <- round(prop.table(segment_order$or_cnt),2)
ggplot(segment_order,aes(x=SHOPPER_SEGMENT_CODE,y=or_cnt,fill=SHOPPER_SEGMENT_CODE)) + geom_bar(stat="identity",colour="black")

5.1 segment 별 회원수¶
In [23]:
segment_cus_order <- order_df %>% distinct(CUSTOMER_NBR,SHOPPER_SEGMENT_CODE) %>% group_by(SHOPPER_SEGMENT_CODE) %>% summarize(or_cnt=n())
# 합쳐서
seg <- merge(segment_customer,segment_order,by="SHOPPER_SEGMENT_CODE")
seg <- seg %>% mutate(avg = round(or_cnt/cu_cnt,2))
ggplot(seg,aes(x=SHOPPER_SEGMENT_CODE,y=avg,fill=SHOPPER_SEGMENT_CODE)) + geom_bar(stat="identity",colour="black")

5.2 월별 판매 수¶
In [24]:
# 월별 판매 수
mon_order <- order_df %>% group_by(ORDER_MON) %>% summarize(cnt =n())
mon_order$ORDER_MON <- as.factor(mon_order$ORDER_MON)
mon_order$per <- round(prop.table(mon_order$cnt),2) * 100
ggplot(data=mon_order,aes(x=ORDER_MON,y=cnt,fill=ORDER_MON)) +geom_bar(stat="identity")

6. 요일별 주문 Count¶
In [25]:
v_day <- order_df %>% group_by(ORDER_DAY) %>% summarize(cnt=n())
v_day$ORDER_DAY = factor(v_day$ORDER_DAY,labels=c("SUN","MON","TUE","WED","THU","FRI","SAT"),ordered=TRUE)
ggplot(v_day, aes(x=ORDER_DAY,y=cnt,fill=ORDER_DAY)) + geom_bar(stat="identity",colour="black")

7. 카테고리별 구매 횟수 5개¶
In [26]:
order_per_cate <- order_df %>% group_by(MERCH_DIV_DESC) %>% summarize(cnt = n()) %>% arrange(desc(cnt))
ggplot(head(order_per_cate), aes(x=MERCH_DIV_DESC,y=cnt,fill=MERCH_DIV_DESC)) + geom_bar(stat="identity",colour="black")

8. 가장 많이 팔린 제품 상위 5개¶
In [27]:
order_per_product <- order_df %>% group_by(PACKING_SLIP_DESC) %>% summarize(cnt = n()) %>% arrange(desc(cnt))
ggplot(head(order_per_product), aes(x=PACKING_SLIP_DESC,y=cnt,fill=PACKING_SLIP_DESC)) + geom_bar(stat="identity")

9. 시간대별 판매 수¶
In [28]:
v_time_cate <- order_df %>% group_by(ORDER_HOUR,MERCH_DIV_DESC) %>% summarize(cnt = n()) # 다른 데서 line plot으로 시간대별로 다르게 표현.
time_order <- v_time_cate %>% group_by(ORDER_HOUR) %>% summarize(cnt = sum(cnt))
ggplot(data=time_order, aes(x=factor(ORDER_HOUR), y=cnt,group=1)) + geom_line(color="red") + geom_point(color="blue")

10. Timezone 별 주문 횟수¶
In [29]:
timezone_order <- order_df %>% group_by(timezone) %>% summarize(cnt = n()) %>% mutate(prob = round((cnt/sum(cnt)),3)*100)
timezone_order
In [48]:
timezone_customer <- customer %>% group_by(timezone) %>% summarize(cnt=n())
timezone_cluster_customer <- customer %>% group_by(timezone,cluster) %>% summarize(cnt = n())
timezone_segment_customer <- customer %>% group_by(timezone,SHOPPER_SEGMENT_CODE) %>% summarize(cnt=n())
df_order_timezone <- data.frame(timezone = timezone_order$timezone, timezone_cnt = timezone_order$cnt)
df_customer_timezone <- data.frame(timezone = timezone_customer$timezone, customer_cnt = timezone_customer$cnt)
df_timezone <- merge(df_customer_timezone,df_order_timezone,by="timezone")
df_timezone <- df_timezone %>% mutate(per_order = round(timezone_cnt / customer_cnt,2))
timezone_order <- left_join(timezone_order,df_timezone[,c(1,4)])
In [50]:
options(repr.plot.height=5)
p1 <- ggplot(timezone_order,aes(x=timezone,y=prob,fill=timezone)) + geom_bar(stat="identity")
p2 <- ggplot(timezone_order,aes(x=timezone,y=per_order,fill=timezone)) + geom_bar(stat="identity")
gridExtra::grid.arrange(p1, p2)

11. Segmnet 요일 구매 패턴¶
In [52]:
options(repr.plot.height=3)
segment_mon_order <- order_df %>% group_by(SHOPPER_SEGMENT_CODE,ORDER_DAY) %>% summarize(or_cnt=n())
segment_mon_order$ORDER_DAY = factor(segment_mon_order$ORDER_DAY,labels=c("SUN","MON","TUE","WED","THU","FRI","SAT"),ordered=TRUE)
ggplot(segment_mon_order,aes(x=SHOPPER_SEGMENT_CODE,y=or_cnt,fill=ORDER_DAY)) + geom_bar(stat="identity",position="dodge")

12 . 광고 시청 유무에 따른 구매 및 전체 광고 흐름¶
In [62]:
air_product <- read.csv("data/Product airtime.csv")
head(air_product)
12-1 시간대별 광고 전체¶
In [63]:
air_product$PRODUCT_START_TMS <- ymd_hm(air_product$PRODUCT_START_TMS)
air_product$PRODUCT_STOP_TMS <- ymd_hm(air_product$PRODUCT_STOP_TMS)
air_product$AIR_DATE <- ymd_hm(air_product$AIR_DATE)
air_product$START_HOUR <- hour(air_product$PRODUCT_START_TMS)
air_product$STOP_HOUR <- hour(air_product$PRODUCT_STOP_TMS)
air_product$AIR_MON <- month(air_product$AIR_DATE)
head(air_product)
In [66]:
total_air_hour <- air_product %>% group_by(START_HOUR) %>% summarize(cnt = n())
total_air_hour$type = "Total_Ad"
ggplot(total_air_hour,aes(x=factor(START_HOUR),y=cnt,group=2)) + geom_line(size = 2,color="red") + geom_point(color="blue",size=2)

In [68]:
# 구매 제품의 방송 시간에 따른 구매 ####
tmp_df <- order_df[!is.na(order_df$AIR_DATE),]
air_time_order <- tmp_df %>% group_by(START_HOUR) %>% summarize(cnt = n())
In [75]:
air_time_order$type="ConnectToSell"
In [76]:
air_df <- rbind(total_air_hour,air_time_order)
air_df$START_HOUR <- factor(air_df$START_HOUR)
In [77]:
ggplot(air_df,aes(x=START_HOUR,y=cnt)) + geom_line(aes(group=type,color=type),size = 2) + geom_point(aes(group=type,color=type),size = 2)

In [53]:
# 광고를 본사람 vs 안본사람 시간대 비교 ####
air_order_df <- order_df[!is.na(order_df$AIR_DATE),]
no_air_order_df <- order_df[is.na(order_df$AIR_DATE),]
air_time_order <- air_order_df %>% group_by(ORDER_HOUR) %>% summarize(cnt=n())
no_air_time_order <- no_air_order_df %>% group_by(ORDER_HOUR) %>% summarize(cnt=n())
air_time_order$type="air"
no_air_time_order$type="noair"
compare_air <- rbind(air_time_order,no_air_time_order)
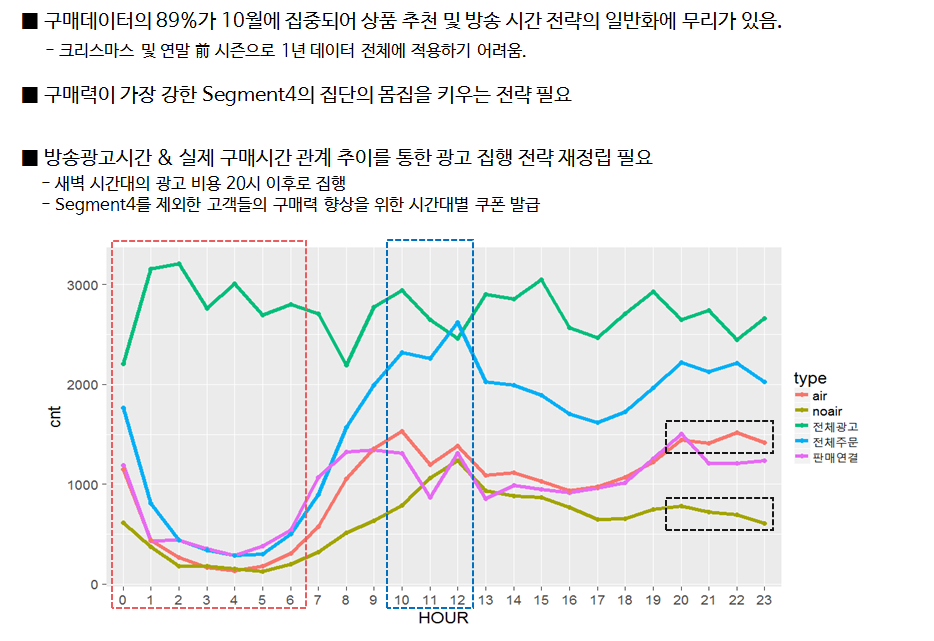
ggplot(compare_air,aes(x=ORDER_HOUR,y=cnt)) + geom_line(aes(group=type,color=type),size = 2) + geom_point(aes(group=type,color=type),size = 2)

전체 주문¶
- 0 ~ 6시 : 타 시간대 대비 광고량 대비 구매량이 현저히 적음
- 10 ~ 12시 : 주문 횟수 > 광고 횟수, 광고 ↑ : 구매 ↑
- 20 ~ 23시 : 광고 유무 -> 구매 영향도 높음, 매출 노ㅠ은 짧은 광고 시간의 상품 노출 필요
In [80]:
names(air_df)[1] <- "HOUR"
names(compare_air)[1] <- "HOUR"
# 전체 주문 확보 ####
total_order <- order_df %>% group_by(ORDER_HOUR) %>% summarize(cnt=n())
names(total_order)[1] <- "HOUR"
total_order$type <- "TotalOrder"
tmp_df <- rbind(air_df,compare_air)
tmp_df <- rbind(tmp_df,total_order)
ggplot(tmp_df,aes(x=HOUR,y=cnt)) + geom_line(aes(group=type,color=type),size = 1) + geom_point(aes(group=type,color=type),size = 1)

Answer the Questions¶
1. What is the next product a customer will buy in the next month given their previous buying behavior and product airtime?¶
- 제품의 경우 같은 Cluster 내 고객들의 구매 내역 중 내가 사지 않은 내역을 추천
In [88]:
order_df <- read.csv("data/order_data_cluster.csv", stringsAsFactors = F)
customer <- read.csv("data/customer_with_cluster.csv",stringsAsFactors = F)
In [85]:
order_df$SHOPPER_SEGMENT_CODE[is.na(order_df$SHOPPER_SEGMENT_CODE)] <- 0
order_df$SHOPPER_SEGMENT_CODE <- as.factor(order_df$SHOPPER_SEGMENT_CODE)
In [31]:
for(i in 1:9){
tmp_df <- order_df %>% filter(cluster==i)
assign(paste0("cluster_",i),tmp_df)
}
In [32]:
for(i in 1:9){
tmp_df <- get(paste0("cluster_",i))
tmp_df <- tmp_df %>% group_by(CUSTOMER_NBR,MERCH_DIV_DESC) %>% summarize(cnt = n()) %>% arrange(CUSTOMER_NBR)
assign(paste0("cluster_cate_",i),as.data.frame(tmp_df))
}
In [33]:
for(i in 1:9){
tmp_df <- get(paste0("cluster_",i))
tmp_df <- tmp_df %>% group_by(CUSTOMER_NBR,PRODUCT_ID) %>% summarize(cnt = n()) %>% arrange(CUSTOMER_NBR)
assign(paste0("cluster_product_",i),as.data.frame(tmp_df))
}
In [34]:
getProductRecommand <- function(x){
custId <- x
custCluster <- customer[customer$CUSTOMER_NBR==custId,]$cluster
in_df <- get(paste0("cluster_product_",custCluster))
in_product_list <- in_df[in_df$CUSTOMER_NBR==custId,]$PRODUCT_ID
in_product_list <- as.data.frame(in_product_list)
other_df <- in_df %>% filter(CUSTOMER_NBR!=custId) %>% group_by(PRODUCT_ID) %>% summarize(cnt = sum(cnt)) %>% arrange(desc(cnt))
other_df <- as.data.frame(other_df)
other_df$percent <- round(prop.table(other_df$cnt),2)
result_df <- other_df %>% filter(!(PRODUCT_ID %in% in_product_list$in_producut_list))
result_df <- left_join(result_df,product)
names(in_product_list)[1] <- "PRODUCT_ID"
in_product_list <- left_join(in_product_list,product)
print(in_product_list[,c(1,2)])
print(head(result_df[,c(1,4,2,3)]))
}
2. In what product category is a customer likely to buy their next product, given their previous buying behavior and product airtime?¶
- 카테고리의 경우 같은 카테고리를 구매할 가능성이 높으므로 연관분석을 통해 추천
2. Category¶
In [35]:
getCateRecommand <- function(x){
custId <- x
custCluster <- customer[customer$CUSTOMER_NBR==custId,]$cluster
if(length(custCluster)==0){
return(0)
}
baskets <- read_baskets(con = paste0("data/item_cate_",custCluster,".txt"),sep = "#", info = c("sequenceID","eventID","SIZE"))
baskets <- cspade(baskets, parameter = list(support = 0.0001), control = list(verbose = TRUE))
baskets_df <- as(baskets, "data.frame")
baskets_df <- baskets_df[order(baskets_df$support,decreasing = T),]
baskets_df$sequence <- gsub(pattern = "<\\{\"","",baskets_df$sequence)
baskets_df$sequence <- gsub(pattern = "\"\\}>","",baskets_df$sequence)
baskets_df$sequence <- gsub(pattern = "\"","",baskets_df$sequence)
last_df <- order_df[order_df$CUSTOMER_NBR==custId,] %>%
arrange(desc(ORDER_DATES)) %>%
select(MERCH_DIV_DESC)
last_cate <- last_df$MERCH_DIV_DESC
support_df <- baskets_df %>% filter(str_detect(sequence,last_cate))
print(paste0(last_cate))
print(head(support_df[-1,]))
}
In [36]:
getRecommand <- function(cate,y){
if(cate=="cate"){
getCateRecommand(y)
}else{
getProductRecommand(y)
}
}
In [37]:
getRecommand("cate",1275)
In [38]:
getRecommand("product",749351)
3. What are the products and categories that sell better in a particular geographic, time zone, and customer segment?¶
3-1 particular geographic¶
In [39]:
v3_1 <- order_df %>%
group_by(STATE,PACKING_SLIP_DESC) %>%
summarize(Pro_cnt=n()) %>%
slice(which.max(Pro_cnt))
In [40]:
v3_1_2 <- order_df %>% group_by(STATE,MERCH_DIV_DESC) %>% summarize(Category_cnt=n()) %>% slice(which.max(Category_cnt))
In [41]:
head(v3_1)
In [42]:
head(v3_1_2)
3-2 Time Zone¶
In [43]:
v3_3 <- order_df %>% group_by(timezone,PACKING_SLIP_DESC) %>% summarize(Hour_P_cnt=n()) %>% slice(which.max(Hour_P_cnt))
v3_4 <- order_df %>% group_by(timezone,MERCH_DIV_DESC) %>% summarize(Hour_C_cnt=n()) %>% slice(which.max(Hour_C_cnt))
In [44]:
head(v3_3)
In [45]:
head(v3_4)
3-3 Segment¶
In [81]:
cs_prodcut <- order_df %>%
group_by(SHOPPER_SEGMENT_CODE,PACKING_SLIP_DESC) %>%
summarize(pro_cnt=n()) %>%
slice(which.max(pro_cnt))
head(cs_prodcut)
In [82]:
cs_category <- order_df %>%
group_by(SHOPPER_SEGMENT_CODE,MERCH_DIV_DESC) %>%
summarize(cate_cnt=n()) %>%
slice(which.max(cate_cnt))
head(cs_category)
3-4 TimeZone & Segment Cross¶
In [96]:
# 3. 타임존, 세그먼트별 잘팔리는 제품.
tzsg_product <- order_df %>% group_by(timezone,SHOPPER_SEGMENT_CODE,PACKING_SLIP_DESC) %>% summarize(tzsg_pro_cnt=n()) %>% slice(which.max(tzsg_pro_cnt))
tzsg_category <- order_df %>% group_by(timezone,SHOPPER_SEGMENT_CODE,MERCH_DIV_DESC) %>% summarize(tzsg_cate_cnt=n()) %>% slice(which.max(tzsg_cate_cnt))
tzsg_product$SHOPPER_SEGMENT_CODE[is.na(tzsg_product$SHOPPER_SEGMENT_CODE)] <- 0
tzsg_category$SHOPPER_SEGMENT_CODE[is.na(tzsg_category$SHOPPER_SEGMENT_CODE)] <- 0
In [97]:
head(tzsg_category)
In [98]:
tail(tzsg_category)
4. Is there a best time of day to sell a particular product or product category?¶
In [99]:
product_per_hour <- order_df %>%
group_by(PACKING_SLIP_DESC,ORDER_HOUR) %>%
summarize(pro_cnt=n()) %>%
slice(which.max(pro_cnt)) %>%
filter(pro_cnt>10) %>% arrange(ORDER_HOUR)
In [100]:
head(product_per_hour)
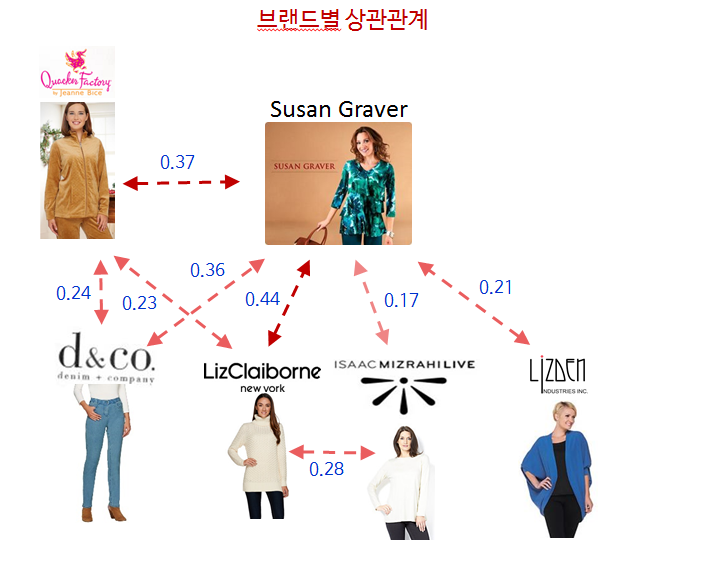
5.What is the brand affinity (personal connection with the brands QVC sells) for QVC’s different customer segments?¶
- 간단하게 답변한다면 Segment별로 좋아하는 Brand를 가지고 오면 된다.
- 하지만 각 브랜드별로 어떤 상관관계가 있고 구매를 촉진 시키는지 Cross Selling이 가능한지 여부를 확인해야한다.
In [101]:
segment_brand <- order_df %>% group_by(SHOPPER_SEGMENT_CODE,BRAND_NAME) %>% summarize(cnt = n()) %>% arrange(SHOPPER_SEGMENT_CODE,desc(cnt))
segment_brand_max <- order_df %>% filter(BRAND_NAME!="Not Known" & BRAND_NAME!="N/A") %>% group_by(SHOPPER_SEGMENT_CODE,BRAND_NAME) %>% summarize(cnt = n()) %>% slice(which.max(cnt))
segment_brand_max$SHOPPER_SEGMENT_CODE[is.na(segment_brand_max$SHOPPER_SEGMENT_CODE)] <- 0
In [102]:
segment_brand_max
In [107]:
count_brand <- order_df %>% group_by(BRAND_NAME) %>% summarize(cnt = n()) %>% arrange(desc(cnt)) %>% head(20)
brand_list <- count_brand$BRAND_NAME
brand_list <- as.data.frame(brand_list)
brand_rel <- order_df %>% filter(BRAND_NAME %in% brand_list$brand_list & BRAND_NAME != "Not Known" & BRAND_NAME != "N/A") %>% group_by(CUSTOMER_NBR,BRAND_NAME) %>% summarize(cnt = n())
brand_rel <- dcast(CUSTOMER_NBR ~ BRAND_NAME, data = brand_rel, value.var = "cnt")
brand_rel[is.na(brand_rel)] <- 0
brand_cor <- round(cor(brand_rel),2)
brand_cor <- as.data.frame(brand_cor)
In [110]:
library(psych)
In [111]:
options(repr.plot.width=8, repr.plot.height=8)
pairs.panels(brand_rel)

In [106]:
brand_cor
결론 : 최적의 방송시간 및 마케팅전략¶