pros & cons¶
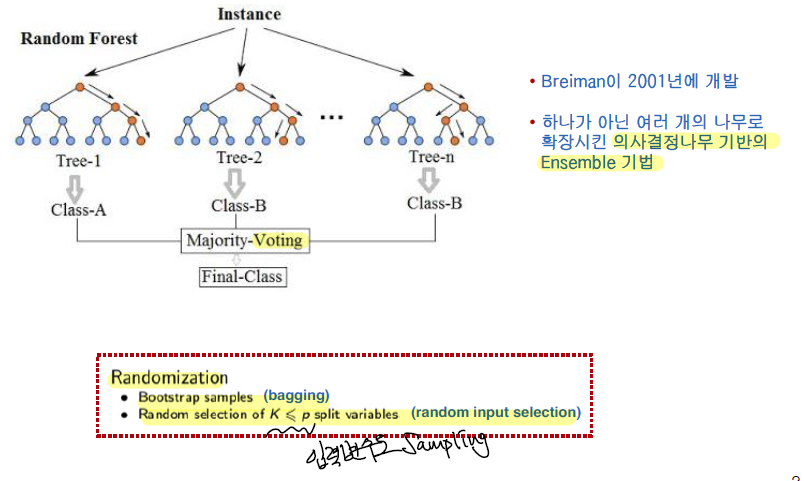
- 숲의 크기(나무의 수)가 커질수록 일반화 오류가 특정 값으로 수렴하게되어 over-fitting을 피할 수 있음
- Decision Tree의 경우 Over fitting의 위험성이 높다.
- 전체 학습용 데이터에서 무작위로 복원 추출된 데이터를 사용함으로써 잡음이나 outlier로부터 크게 영향을 받지 않음
- 분석가가 입력변수 선정으로부터 자유로울 수 있음
- Class의 빈도가 불균형일 경우 타 기법에 비해 우수한 예측력을 보임
- 최종 결과에 대한 해석이 어려움
- Too many trees
- 성능이 중요한 요소이다 Random Forest의 경우
considered heuristics¶
In [3]:
library(randomForest)
library(caret)
library(ROCR)
In [4]:
cb <- read.delim("../1022_Decision Tree_2/Hshopping.txt", stringsAsFactors=FALSE)
colnames(cb) <- c("ID","SEX","AGE","AMT","STAR","REFUND") # Jupyter note Font Error using Korean
cb$REFUND <- factor(cb$REFUND)
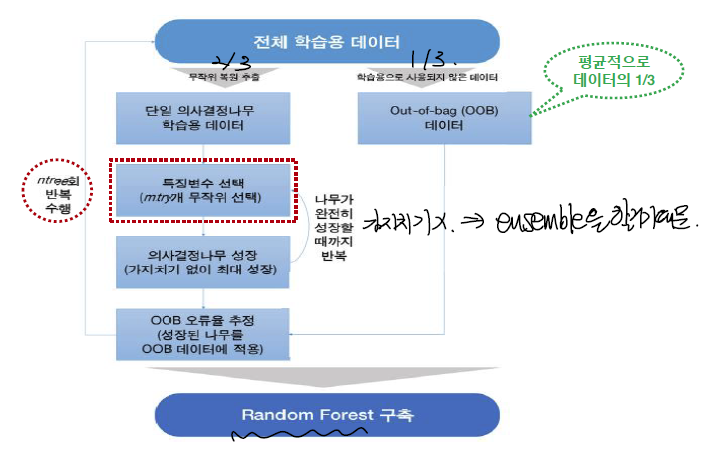
- Sampling
In [5]:
set.seed(1)
inTrain <- createDataPartition(y=cb$REFUND, p=0.6, list=FALSE)
cb.train <- cb[inTrain,]
cb.test <- cb[-inTrain,]
nrow(cb.train)
nrow(cb)
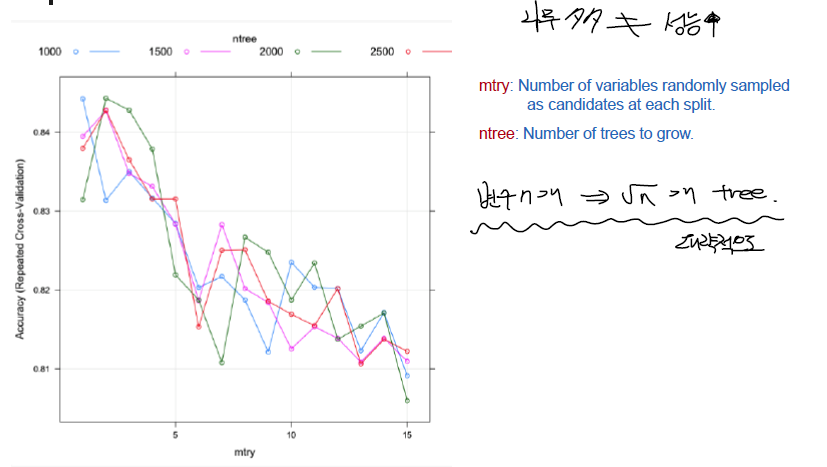
- 50개의 Tree생성.
- 트리 개수는 ntree, 가지를 칠 때 고려할 변수의 갯수는 mtry로 각각 정한다.
- OOB(Out of Bag Sample) estimate of error rate: 9.3% -> 50개 트리 오류의 평균
In [6]:
set.seed(123)
rf_model <- randomForest(REFUND ~. -ID, data=cb.train, ntree = 50, mtry=2)
rf_model
- Green : Worst
- Black : Overall
- Red : Best
In [22]:
options(repr.plot.width=5, repr.plot.height=4)
plot(rf_model)

In [23]:
importance(rf_model) #중요도 퍼센트로 표현.
- 엔트로피 값은 경우 엔트로피 값이 높으면 불순 낮으면 순수
- Gini 도 엔트로피가 동일하다.
- Gini값이 높을 수록 영향도가 높다.
In [25]:
varImpPlot(rf_model)

In [26]:
cb.test$rf_pred <- predict(rf_model, cb.test, type="response")
confusionMatrix(cb.test$rf_pred, cb.test$REFUND)
In [27]:
cb.test$rf_pred_prob <- predict(rf_model, cb.test, type="prob")
rf_pred <- prediction(cb.test$rf_pred_prob[,2],cb.test$REFUND)
rf_model.perf1 <- performance(rf_pred, "tpr", "fpr") # ROC-chart
rf_model.perf2 <- performance(rf_pred, "lift", "rpp")
In [31]:
options(repr.plot.width=8, repr.plot.height=4)
par(mfrow=c(1,2))
plot(rf_model.perf1, colorize=TRUE); abline(a=0, b=1, lty=3)
plot(rf_model.perf2, colorize=TRUE); abline(v=0.4, lty=3)

- AUC : Area under the ROC curve.
In [32]:
performance(rf_pred, "auc")@y.values[[1]]