SVM : Support Vector Machine¶
- Using e1071 packages
Intro¶
- SVM(Support Vector Machine)은 지도학습모형(supervised learning)중 하나로 분류 (classification)와 회귀(regression)에 응용하여 데이터를 분류한다.
- 개요
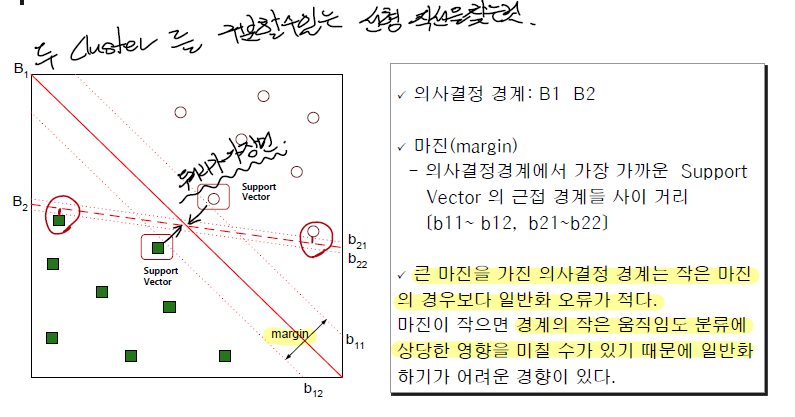
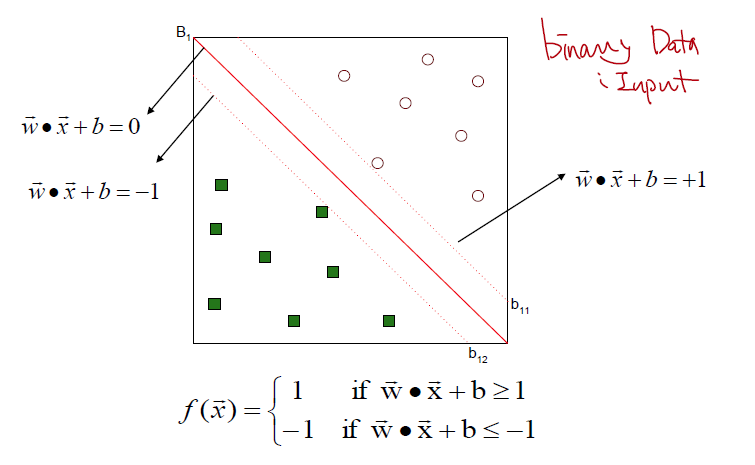
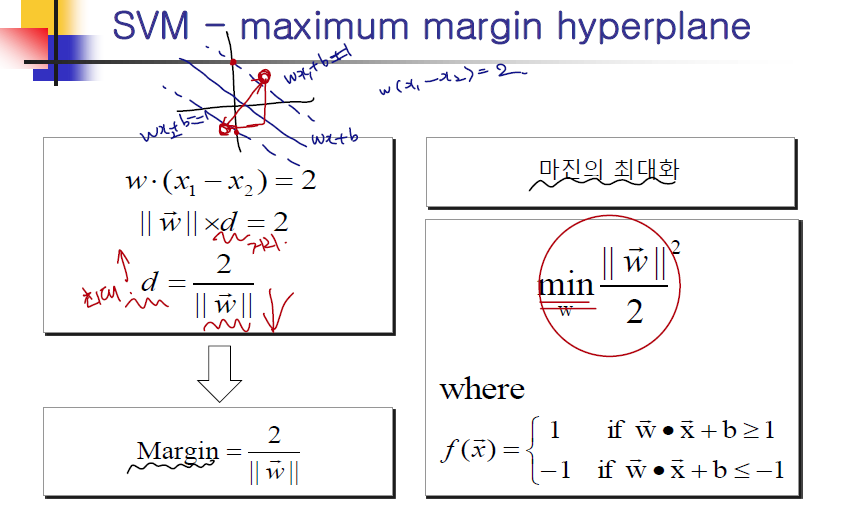
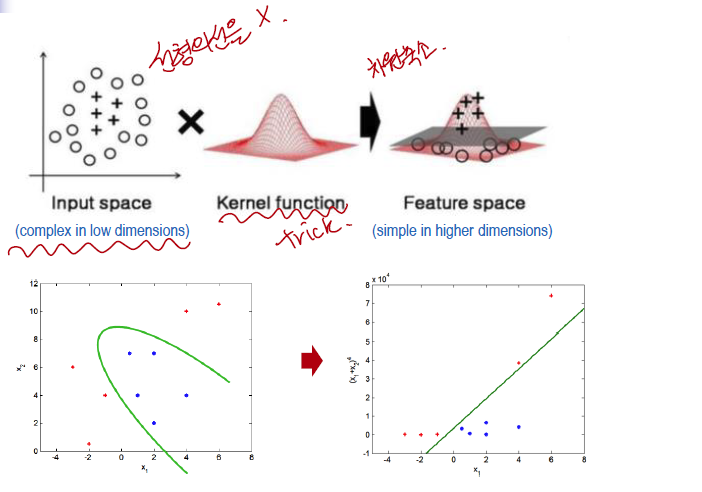
두 카테고리 중 어느 하나에 속한 데이터의 집합이 주어졌을 때, SVM 알고리즘은 주어진 데이터 집합을 바탕으로 하여 새로운 데이터가 어느 카테고리에 속할지 판단하는 비확률적 이진 선형 분류 모델을 만든다. 만들어진 분류 모델은 데이터가 사상된 공간에서 경계로 표현되는데 SVM 알고리즘은 그 중 가장 큰 폭을 가진 경계를 찾는 알고리즘이다. SVM은 선형 분류와 더불어 비선형 분류에서도 사용될 수 있다. 비선형 분류를 하기 위해서 주어진 데이터를 고차원 특징 공간으로 사상하는 작업이 필요한데, 이를 효율적으로 하기 위해 '커널 트릭'을 사용하기도 한다. - 특징
√. 기존의 지도학습모형과 같이 예측을 부분에서 활용될 수 있으며 기계학습 부분에서 다른 모델에 비해서 예측률이 높다고 알려져 있다. √. 넓은 형태의 데이터 셋(많은 예측 변수를 가지고 있는)에 적합하다. √. 모델을 생성할 때는 기본적인 설정사항을 이용해 비교적 빨리 모형을 생성할 수 있다. √. 실제 응용에 있어서 인공신경망 보다 높은 성과를 내고 명백한 이론적 근거에 기반하므로 결과 해석이 상대적으로 용이하다.


considered heuristics¶
In [6]:
library(e1071)
library(caret)
library(ROCR)
In [7]:
cb <- read.delim("../1022_Decision Tree_2/Hshopping.txt", stringsAsFactors=FALSE)
colnames(cb) <- c("ID","SEX","AGE","AMT","STAR","REFUND") # Jupyter note Font Error using Korean
cb$REFUND <- factor(cb$REFUND)
set.seed(1)
inTrain <- createDataPartition(y=cb$REFUND, p=0.6, list=FALSE)
cb.train <- cb[inTrain,]
cb.test <- cb[-inTrain,]
nrow(cb.train)
nrow(cb)
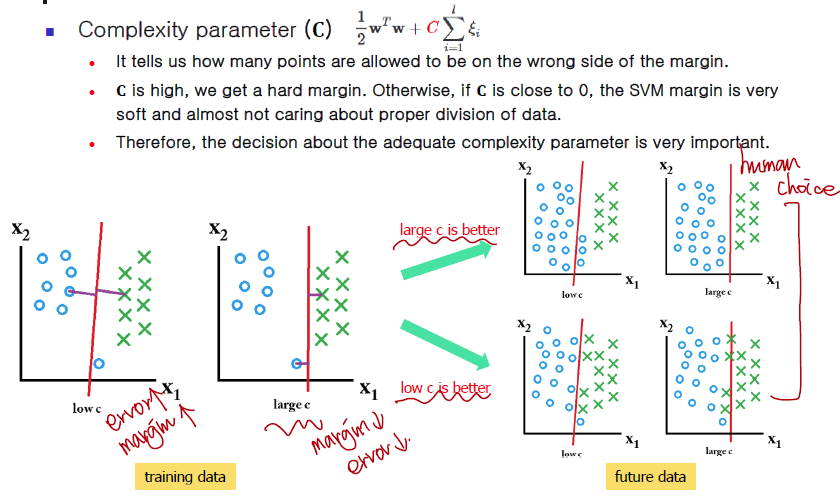
- cost = cost of constraints violation (default: 1)
- it is the ‘C’-constant of the regularization term in the Lagrange formulation.
- cost는 과적합을 막는 정도를 지정하는 파라미터 이다.
- 즉 cost는 잘못 분류하면 얼마만큼의 비용을 지불할 것인지 결정하는 것이다.
- Number of Support Vectors: 77
- 77개의 Support Vectors를 생성
- 45 / 32개로 구분
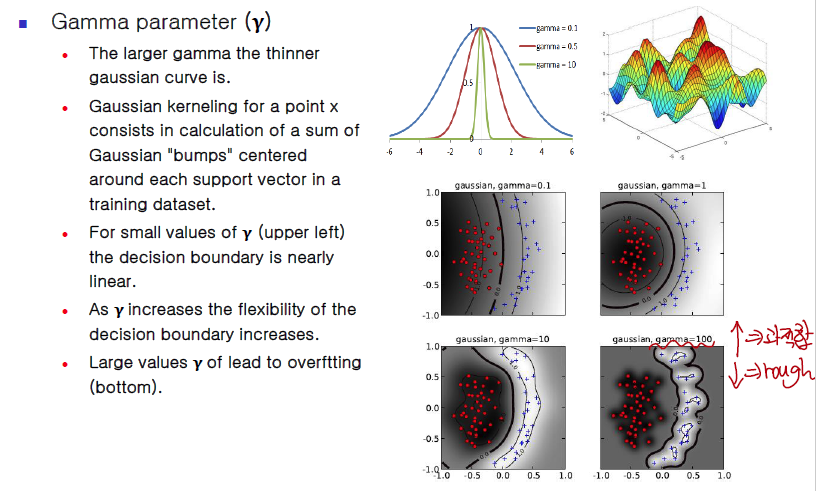
- gamma는 기울기 정도로 이해하면 될 것 같고,
In [10]:
svm_model <- svm(REFUND ~ SEX+AGE+AMT+STAR, data=cb.train, cost=100, gamma=1, probability = T)
summary(svm_model)
In [13]:
options(repr.plot.height=5, repr.plot.width=5)
plot(svm_model, data=cb.train, AMT ~ AGE)

In [14]:
cb.test$svm_pred <- predict(svm_model, cb.test)
In [17]:
confusionMatrix(cb.test$svm_pred, cb.test$REFUND)
postResample¶
- Given two numeric vectors of data, the mean squared error and R-squared are calculated. For two factors,
the overall agreement rate and Kappa are determined. - Kappa 값의 범위는 -1과 1 사이입니다. Kappa 값이 클수록 합치도가 강합니다.
- Kappa 값에 따라 다음과 같이 결론을 내릴 수 있습니다.
- Kappa= 1이면 완전하게 합치하는 것입니다.
- Kappa = 0이면 합치가 우연히 발생하기를 기대하는 것과 같습니다.
- Kappa < 0이면 합치가 우연히 발생하기를 기대하는 것보다 약합니다. 이러한 경우는 거의 발생하지 않습니다.
In [19]:
postResample(cb.test$svm_pred, cb.test$REFUND)
In [20]:
options(repr.plot.height=5, repr.plot.width=8)
par(mfrow=c(1,2))
cb.test$svm_pred_prob <- attr(predict(svm_model, cb.test, probability=TRUE), "probabilities")[,2] # Get Probabilities
svm_pred <- prediction(cb.test$svm_pred_prob, cb.test$REFUND)
svm_model.perf1 <- performance(svm_pred, "tpr", "fpr") # ROC-chart
svm_model.perf2 <- performance(svm_pred, "lift", "rpp")
plot(svm_model.perf1, colorize=TRUE); abline(a=0, b=1, lty=3)
plot(svm_model.perf2, colorize=TRUE); abline(v=0.4, lty=3)

In [21]:
performance(svm_pred, "auc")@y.values[[1]]
tune.svm¶
- 사전정보가 없을 때 돌려보고 나오는 수치들을 활용하여 근방에서 다시 돌려본다.
- gamma, cost 값들에게 vector형태로 입력이 가능하다.
In [23]:
tune.svm(REFUND ~ SEX+AGE+AMT+STAR, data=cb.train, gamma=seq(.5, .9, by=.1), cost=seq(100,1000, by=100))