<
Using "C50", "caret" & "ROCR" packages¶
- createDataPartition() - caret package
- C5.0() - C50 package
- summary() - C50 package
- C5imp() - C50 package
- plot() - C50 package
- predict() - C50 package
- confusionMatrix() - caret package
- prediction() - ROCR package
- performance() - ROCR package
- plot() - ROCR package
In [2]:
library(C50)
library(caret)
library(ROCR)
In [3]:
cb <- read.delim("Hshopping.txt",stringsAsFactors = F)
cb$반품여부 <- as.factor(cb$반품여부)
In [14]:
colnames(cb) <- c("ID","SEX","AGE","AMT","APP","REFUND")
In [15]:
head(cb)
train / test data split¶
In [17]:
set.seed(1) # seed를 고정해야 동일한 샘플링을 가질 수 있다.
inTrain <- createDataPartition(y=cb$REFUND,p=0.6,list=F)
head(inTrain)
In [18]:
cb.train <- cb[inTrain,]
cb.test <- cb[-inTrain,]
In [19]:
dim(cb.train); dim(cb.test)
C5.0의 함수 파라미터를 생성하는 함수 C5.0Control¶
Winnowing
- 입력 필드에 대해서 사전에 필드가 유용한지 측정한 다음 유용하지 않는 경우 배제하고 모델링
- 입력필드가 많을 경우 유용
- 사용법: C5.0Control함수에서 winnow 파라미터를 True로 지정
Pruning severity
- 지역적 가지치기의 강도를 조정
- 이 값이 작으면 작을수록 가지치기 강도가 강해져서, Over-fitting의 가능성이 적어지지만,대신 가지가 적게 되어 정확도가 떨어질 수 있음
- 사용법: C5.0Control함수에서 CF 파라미터를 0에서 1사이의 값으로 설정(default는 0.25)
Global Pruning
- 전역적 가지치기 여부를 결정
- 전역적 가지치기는 전체적으로 만들어진 Tree 구조에서 가지치기를 수행하는데 강도가 약한 sub-tree자체를 삭제
- 사용법: C5.0Control함수에서 noGlobalPruning 파라미터를 설정(default는 FALSE)
In [20]:
c5_options <- C5.0Control(winnow = FALSE, noGlobalPruning = FALSE)
c5_model <- C5.0(REFUND ~ SEX+AGE+AMT+APP, data=cb.train,control=c5_options, rules=FALSE)
In [21]:
summary(c5_model)
- size : 트리의 깊이
- 8.0%가 틀리고 92%를 맞췄다.
- 대각선 194, 83이 맞춘 것이다.
In [26]:
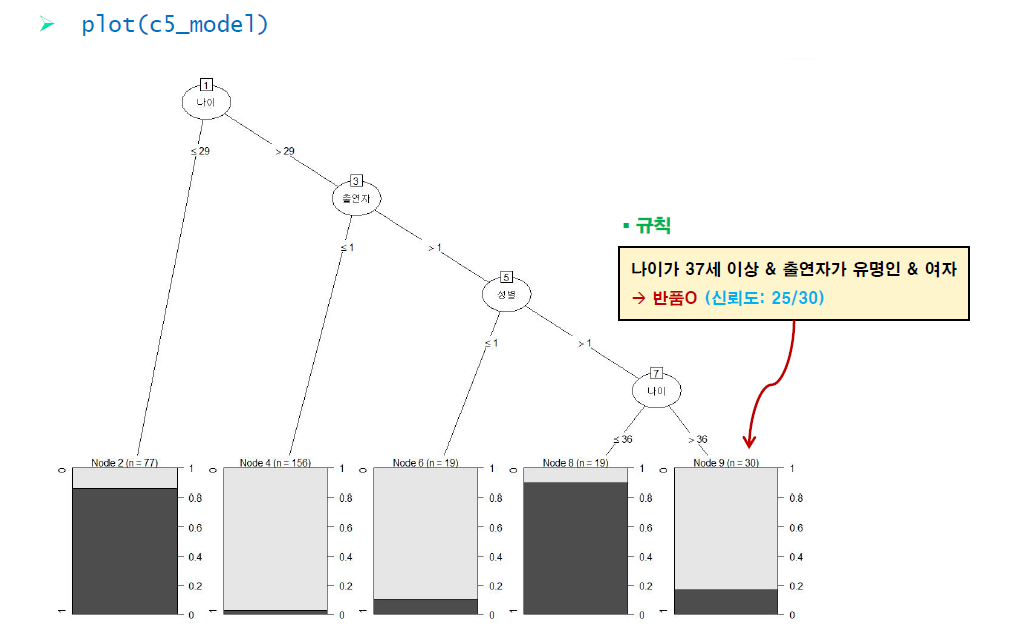
options(repr.plot.height=5)
plot(c5_model)

< <
<
In [27]:
c5_model_2 <- C5.0(REFUND ~ SEX+AGE+AMT+APP, data=cb.train,control=c5_options, rules=T)
summary(c5_model_2)
In [29]:
c5_model_3 <- C5.0(REFUND ~ SEX+AGE+AMT+APP, data=cb.train,control=c5_options, rules=F, trials=3)
summary(c5_model_3)
C5.0 Options¶
- CF=0.7 가지치기 정도를 낮춘다. Strict 숫자가 높을 수록 정도를 낮춘다.
- Strict 할수록 해당 데이터에 대해서 잘 fitting되지만 다른 데이터에는 좋지 않을 수도있다.
In [30]:
c5_options_2 <- C5.0Control(winnow = F, noGlobalPruning = F, CF=0.7)
c5_model_4 <- C5.0(REFUND ~ SEX+AGE+AMT+APP, data=cb.train,control=c5_options_2, rules=FALSE)
In [31]:
summary(c5_model_4)
Global Pruning 전역적 가지치기.¶
- 지역적 가지치기는 부모와 자식간의 가지치기 ( 개별 각각으로)
- 전체 나무 모양을 보고 트리의 깊이가 있어도 해당 부분을 칠수도있다.
< <
< <
< <
< <
< <
<
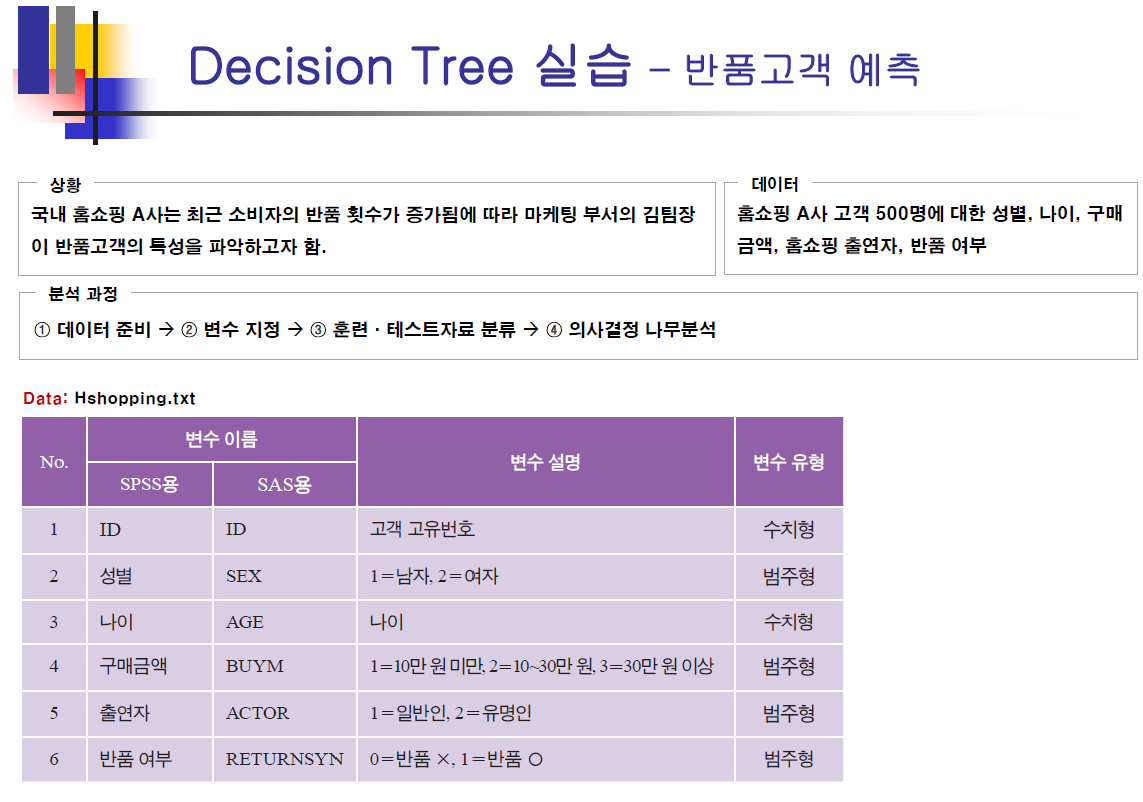
반품고객 예측 및 평가¶
In [32]:
cb.test$c5_pred <- predict(c5_model,cb.test,type="class")
cb.test$c5_pred_prob <- round(predict(c5_model,cb.test,type="prob"),2)
정확도 확인¶
In [33]:
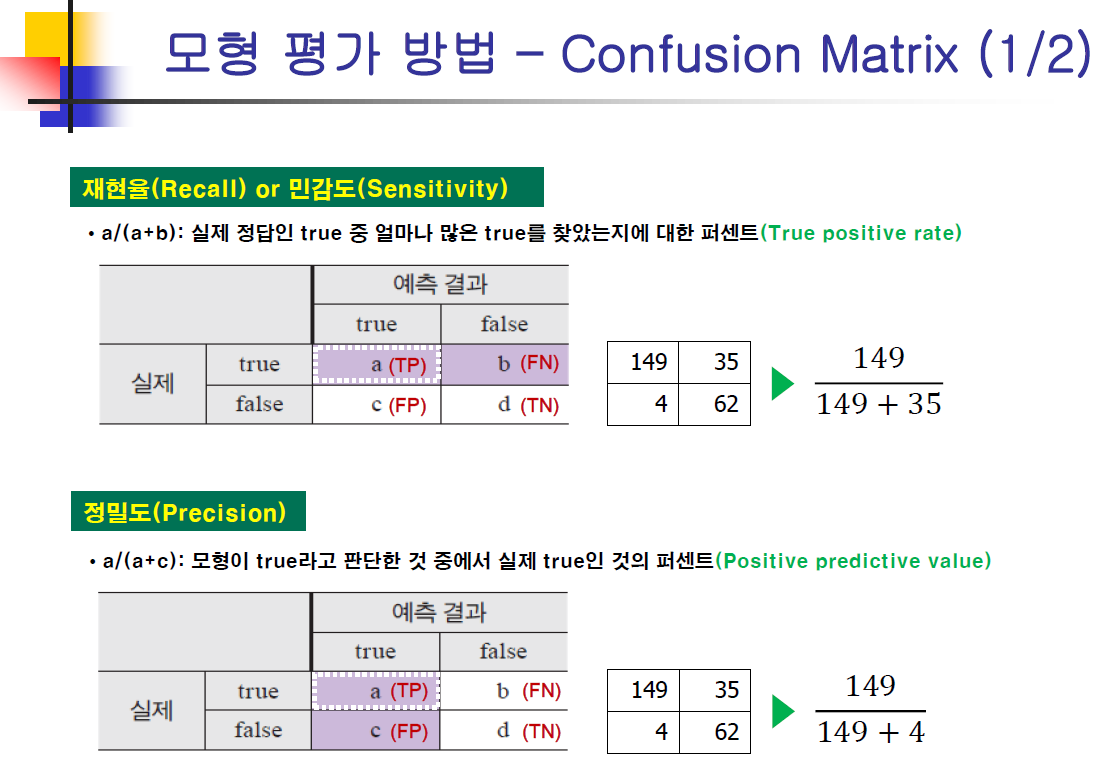
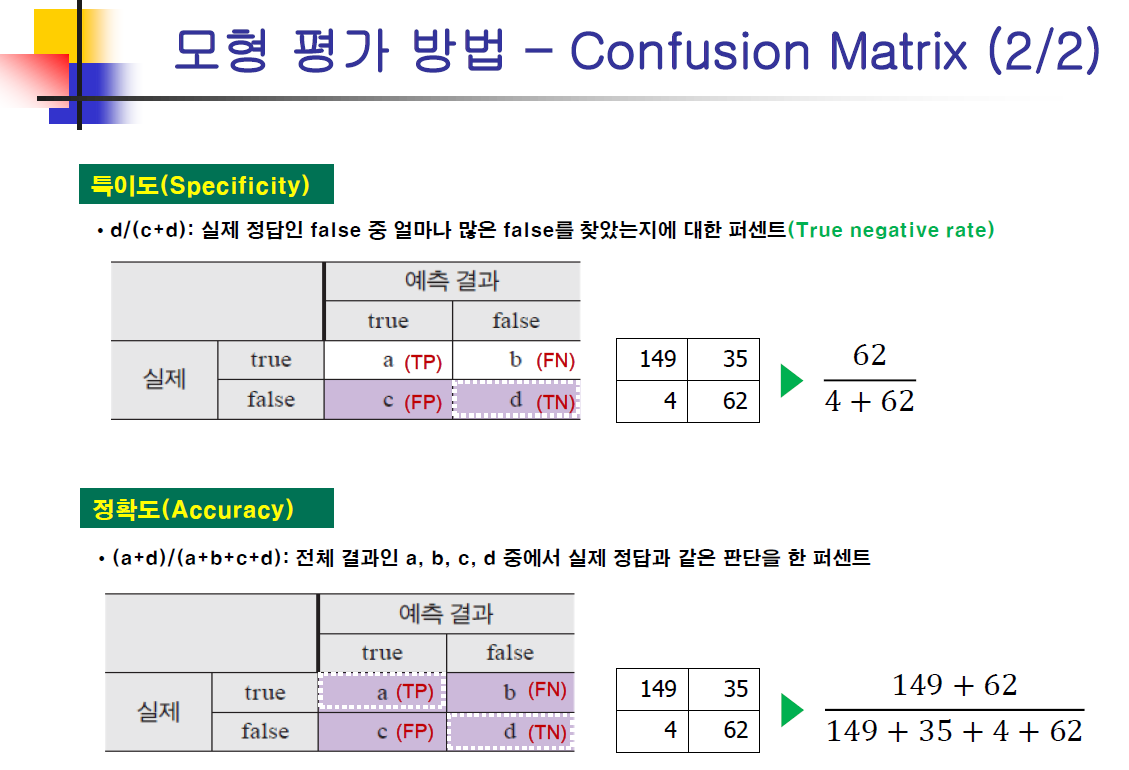
confusionMatrix(cb.test$c5_pred, cb.test$REFUND)
시각적 확인¶
In [35]:
c5_pred <- prediction(cb.test$c5_pred_prob[,2], cb.test$REFUND)
c5_model.perf1 <- performance(c5_pred,"tpr","fpr") # Roc curve
c5_model.perf2 <- performance(c5_pred,"lift","rpp") # Lift chart
par(mfrow=c(1,2))
plot(c5_model.perf1,colorize=T)
plot(c5_model.perf2,colorize=T)

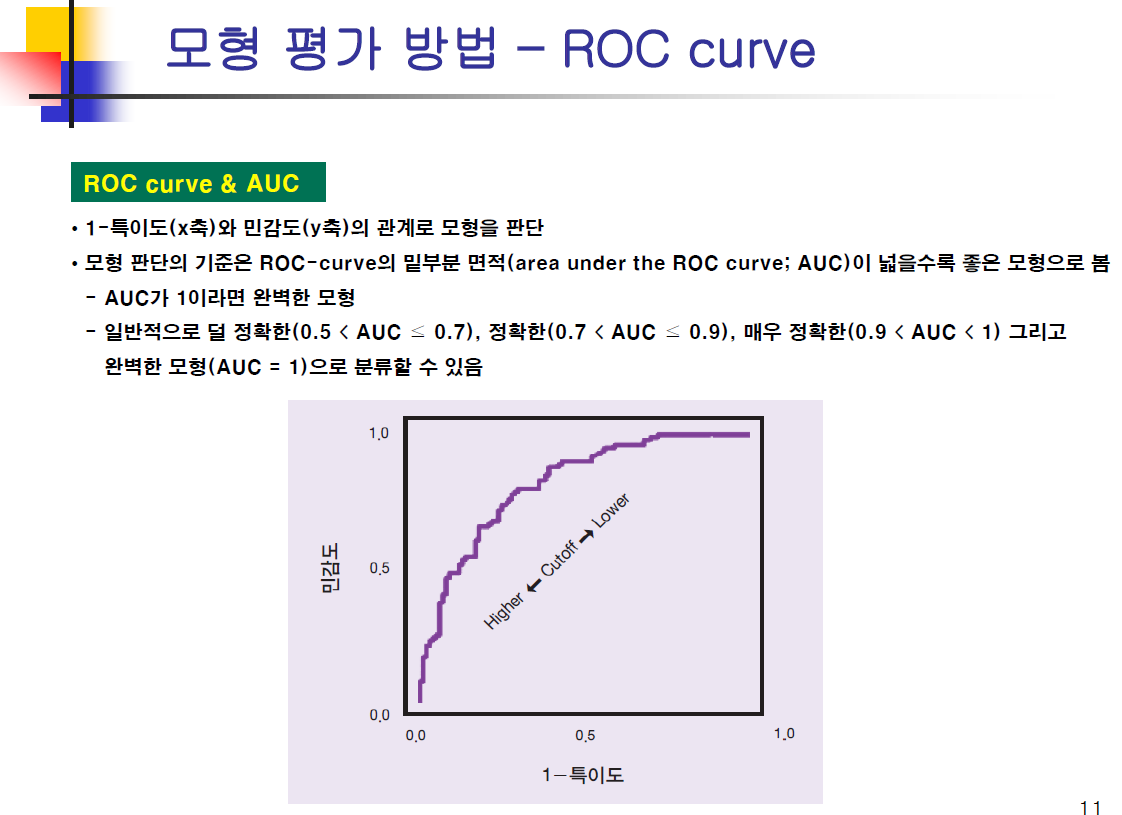
- 커브 아래의 면적 면적이 높을 수록 좋은 모형이 된다. roccurve에서
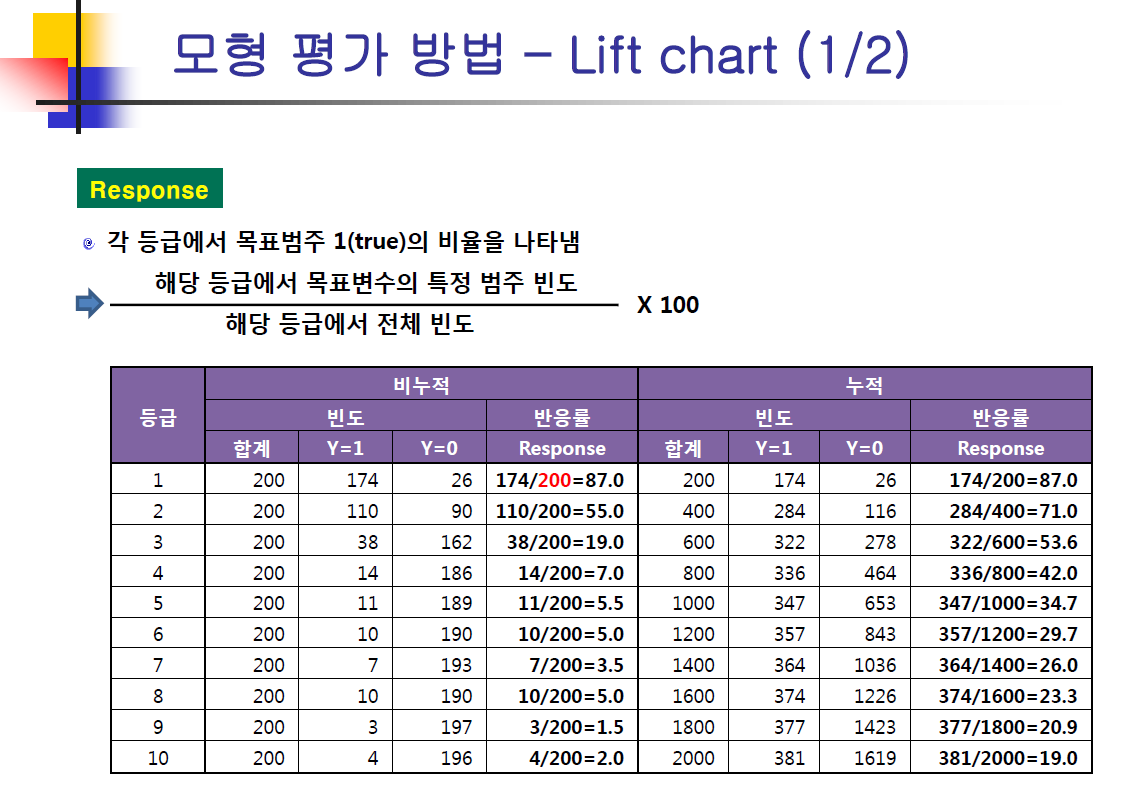
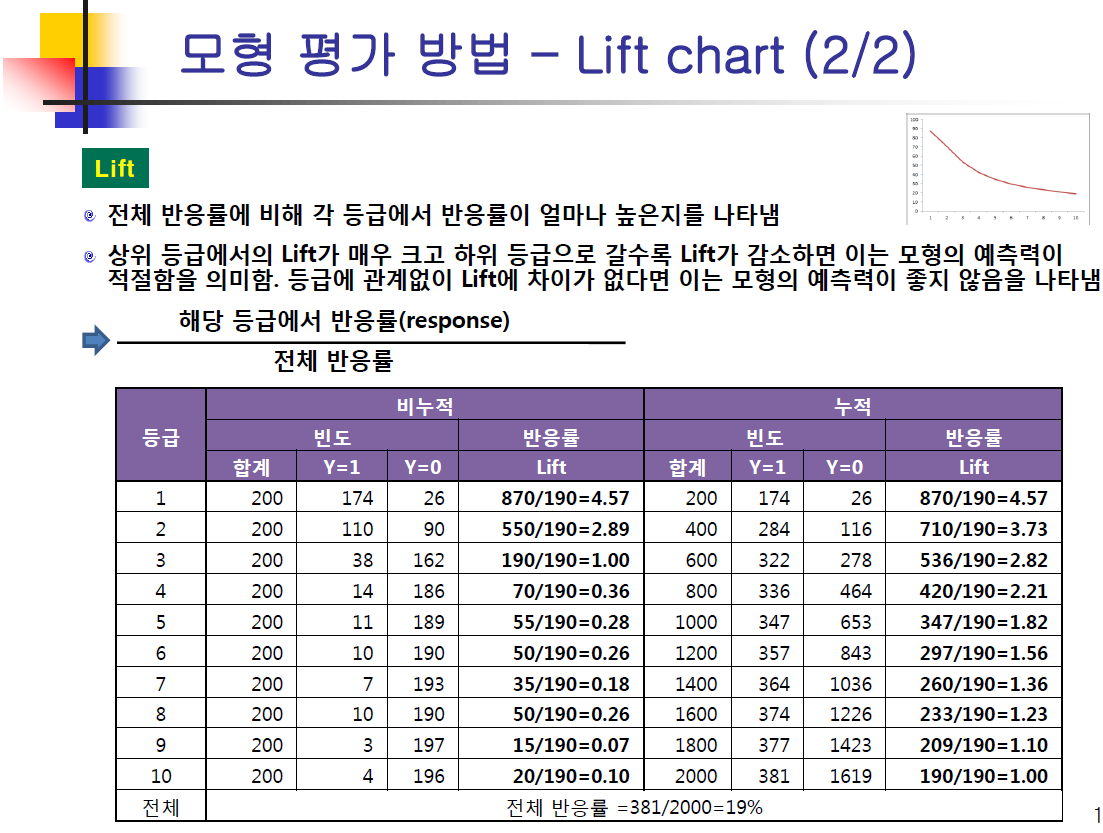
- lift chart는 급격하게 떨어지면 좋은 모형이다.
In [36]:
performance(c5_pred,"auc")@y.values[[1]]
괜찮은 그래프 그리기¶
In [38]:
library(Epi)
In [40]:
ROC(form=cb.test$REFUND~c5_pred_prob[,2], data=cb.test, plot="ROC")
