Concept of Data Mining¶

Data Mining¶
- 대량의 데이터로부터 새롭고 의미 있는 정보를 추출하여 의사결정에 활용하는 작업
- 지식발견
- 정보발견, 정보수학
- 정보고고학, 자료패턴처리
데이터마이닝의 다양한 정의¶
- 데이터베이스에서 지기발견은 데이터에 있는 유효하고, 잠재적으로 이용가능하며 궁극적으로 이해할 수 있는 패턴을 식별하는 중요한 프로세스 (Fayyad et al., “Advance in Knowledge Discovery and Data Mining,”1996)
- 데이터 마이닝은 비즈니스 문제를 해결하기 위해 현재 조치를 취할 수 있고,명시적이며 새로운 정보를 추출하기 위해 세부적인 데이터를 분석하는 프로세스이다.(NCR)
- 데이터 마이닝은 큰 데이터베이스로부터 이전에 알려지지 않고, 궁극적으로이해가능한 정보를 추출 및 중요한 비즈니스 의사결정을 하는 프로세스이다.(IBM)
- 데이터 마이닝은 비즈니스 우위를 위해 이전에 알려지지 않은 패턴을 발견하기 위해 많은 양의 데이터를 선택하고, 탐색 및 모델링하는 프로세스이다.(SAS Institute)
- 데이터 마이닝은 기업의 경영 활동에서 발생하는 대용량 데이터에서 데이터간의 관계·패턴·규칙 등을 찾아내고 모형화해 유용한 경영 정보로 변환시키는 일련의 과정이다.
Statistics Vs DM¶
- 전통적 통계분석
- 대상집단이 있으며, 모집단의 분포 혹은 모형 등 여러 가지 가정을 전제로 하게 되며 이 전제 조건하에서 분석을 실시
- =>표본의 관찰을 통해 모수 전체를 추론하는 과정
- 데이터마이닝
- 표본조사/실험에서 필연적으로 수반되는 분포라든가 모형에 대한 전제조건이 필요하지않음
- =>모집단의 전체자료를 이용한 정보화하는 과정
SQL / OLAP / DataMining¶
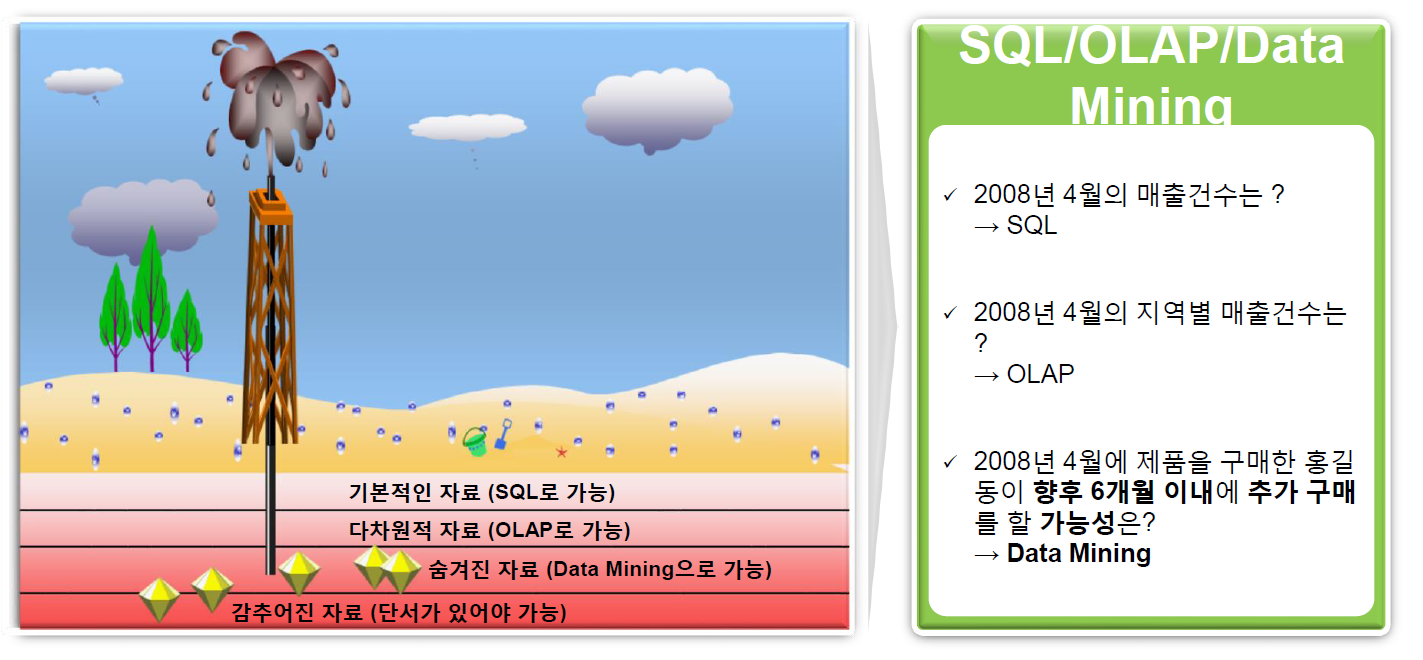
What Problems can DM Solve ?¶
- 대부분의 문제에 대해서 결과를 예측한다. 또는 확률, 의사결정, 수치를 에측한다.
Data Mining Process¶
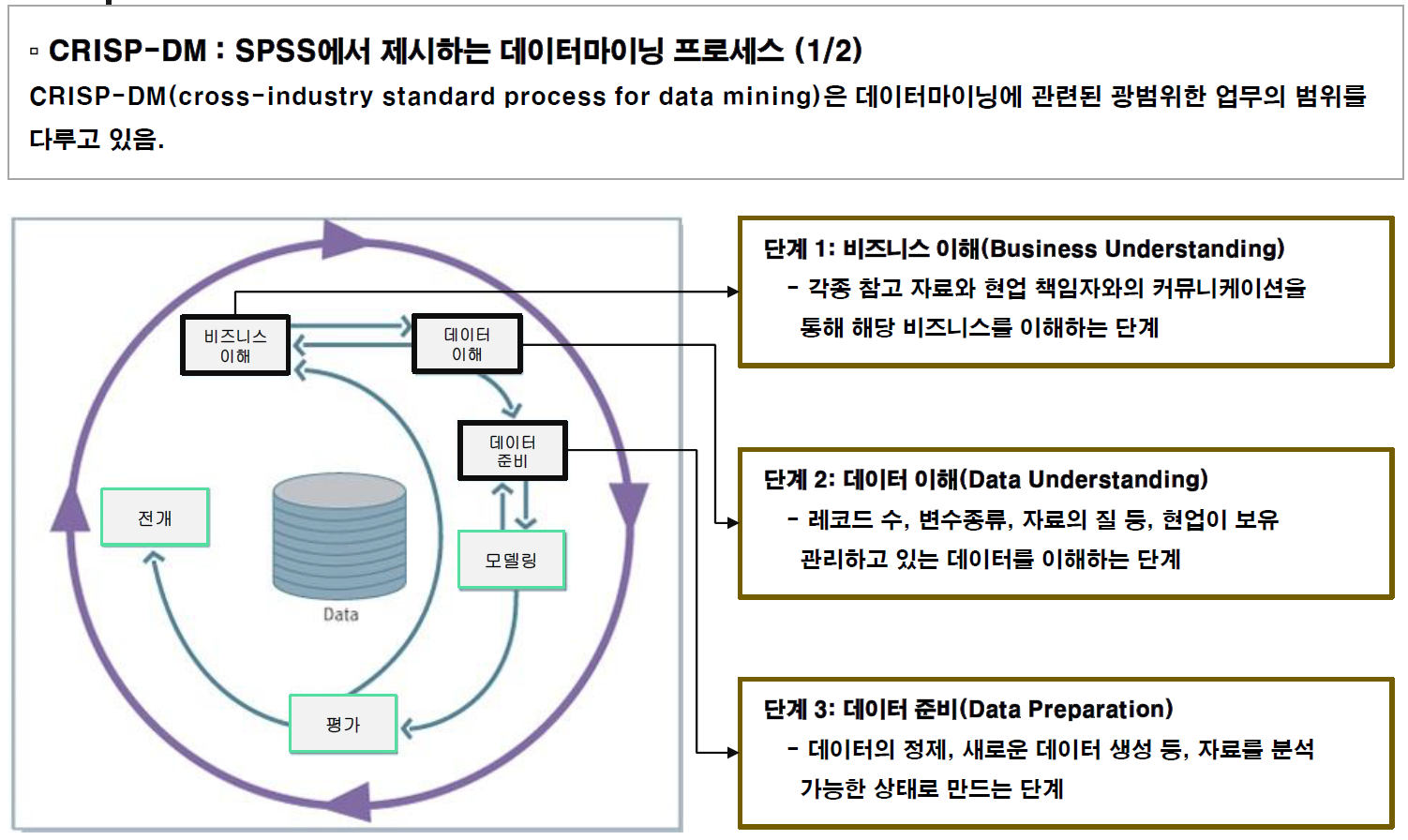
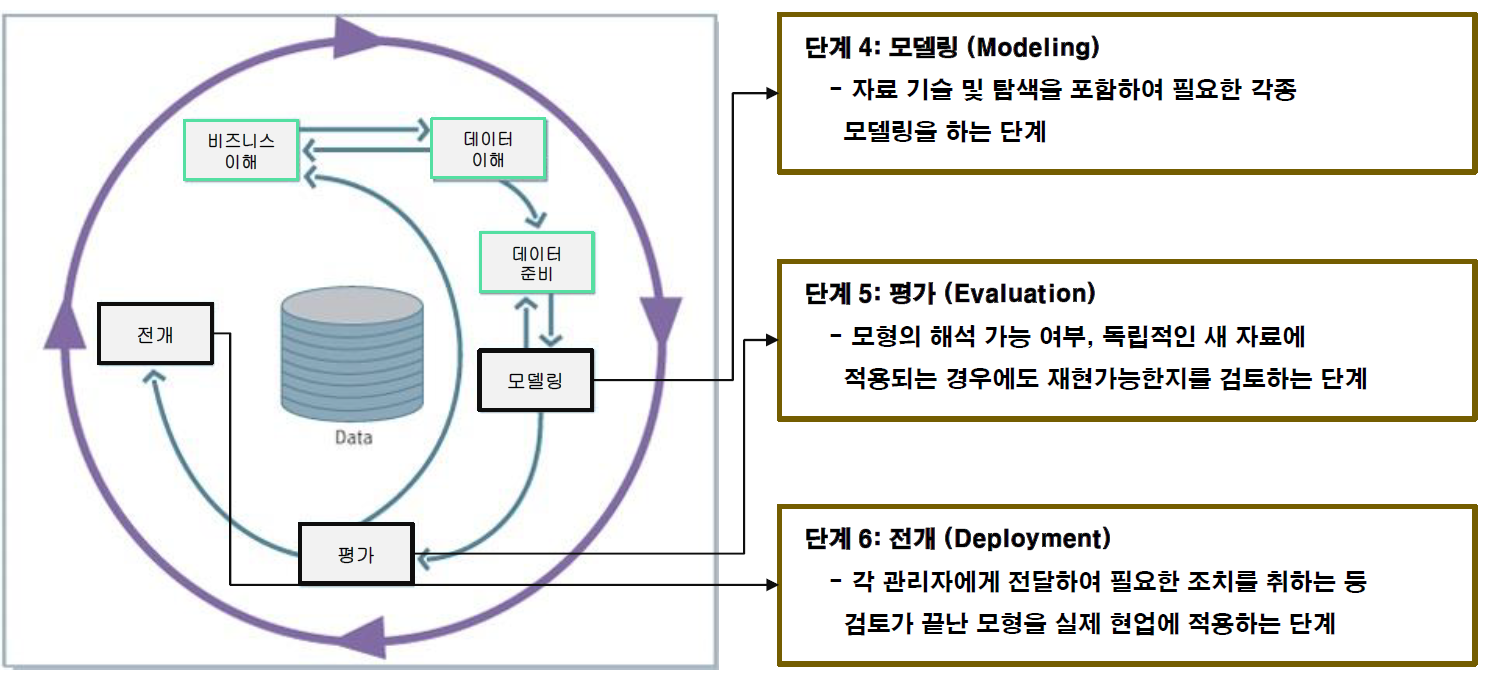
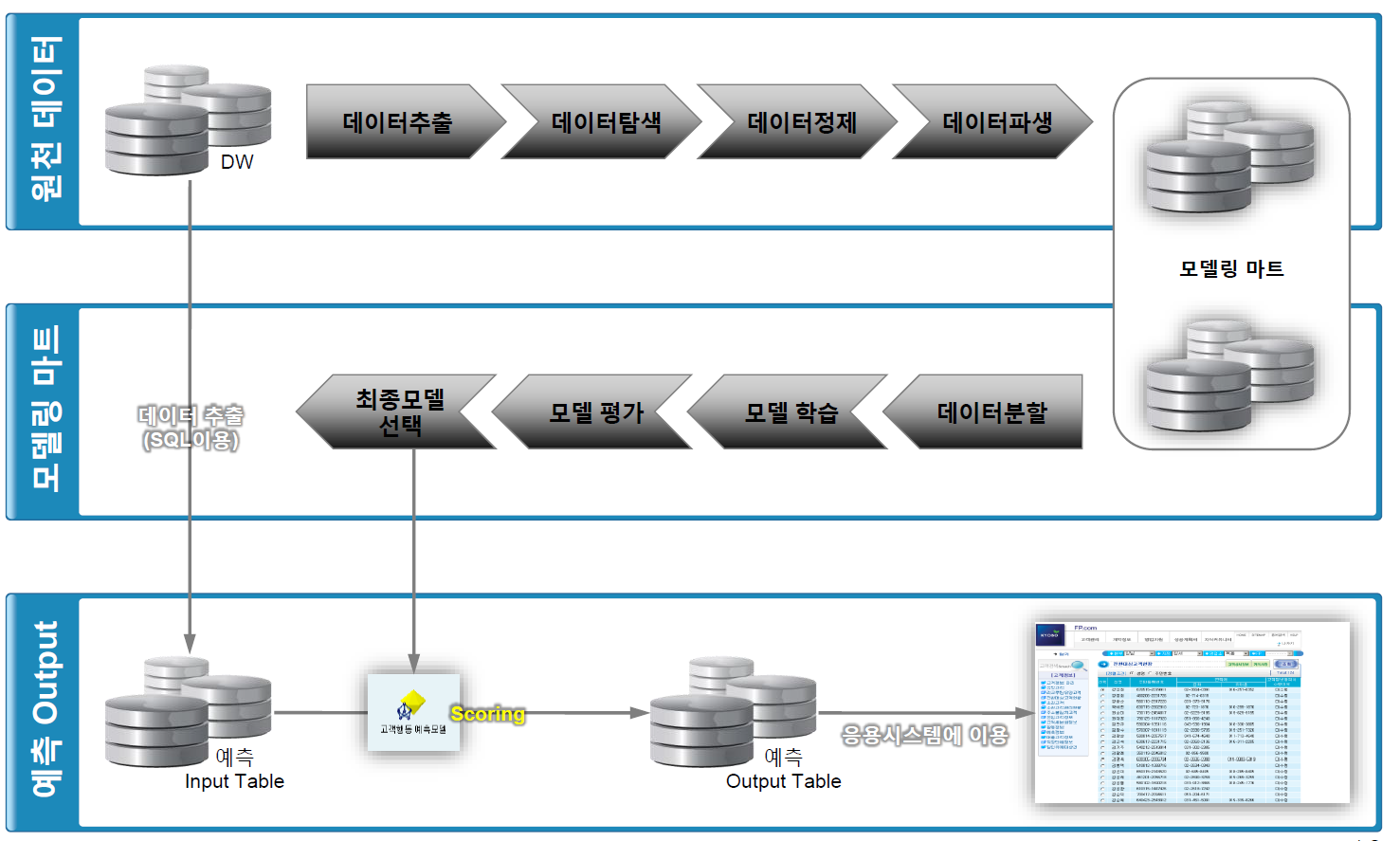
Predictive Modeling Process¶
데이터마이닝 기법의 종류¶
Supervised Modeling (지도 학습, Predictive Analytics)¶
- Estimation / Prediction (추정/예측 : 연속형)
- Linear Regression, Neural Network
Classification / Prediction (분류/예측 : 이산형)
- Decision Tree(C5.0), Neural Network, SVM
<font size=3 color='green'>용어의 유례 : 어리아이가 말을 배우는 과정 ( 엄마가 Supervisor ) </font>
unsupervised Modeling ( 비지도 학습 , descriptive Analytics)¶
- Clustering(군집화)
- K-Means, SOM
- Association rule Mining ( 연관규칙 탐사 )
- Sequential rule Mining ( 연속규칙 탐사 )
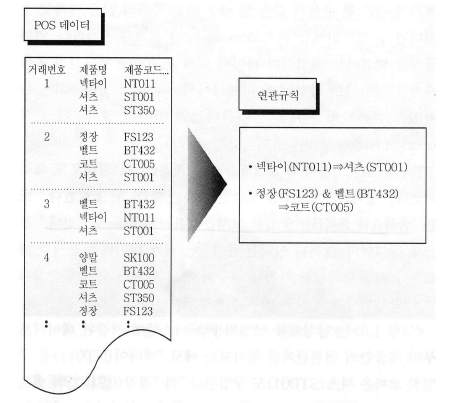
1. 연관 규칙 탐사 (Association Rule Mining)¶
- 정의
- 데이터 안에 존재하는 항목간의 종속 관계를 찾아내는 작업
- 장바구니 분석(Market Basket Analysis)
- 고객의 장바구니에 들어있는 품목 간의 관계를 발견
- 규칙의 표현
- 항목 A와 품목 B를 구매한 고객은 품목 C를 구매한다.
- (품목A) & (품목B) => (품목C)
- 연관규칙의 활용
- 제품이나 서비스의 교차 판매
- 매장진열, 첨부우편
- 사기적발
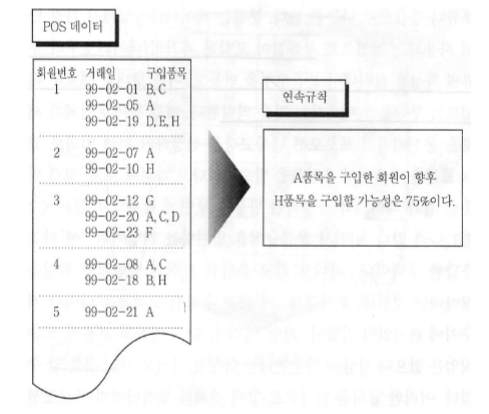
2. 연속규칙탐사 ( Sequential Rule Mining )¶
- 정의
- 연관 규칙에 시간 관련 정보가 포함된 형태
- 규칙의 표현
- 새 냉장고를 구입한 고객 중 한달 이내에 새 오븐을 구입하는 경향이 많다.
- 연속 규칙의 활용
- 타겟 마케팅
- 일대일 마케팅
- 전제조건
- 고객의 구매내역(History) 정보가 반드시 필요함.
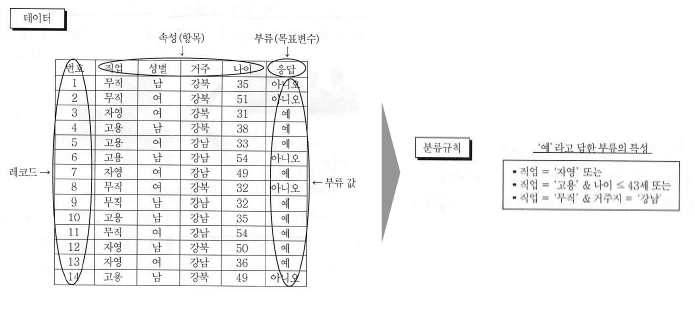
3. 분류 ( Classification )¶
- 분류 프로세스
- 과거의 데이터를 부류로 구분
- 부류별 특성을 발견
- 분류 모형 생성
- 모형을 토대로 새로운 레코드의 분류 값 예측
- 분류의 활용
- 고객의 신용등급 분류
- 기업의 도산 예측
- 프로모션 대상고객 선정
- 분류 기법
- 의사결정나무 (Decision Tree)
- 인공신경망 (Neural Network)
- SVM(Support Vector Machine)
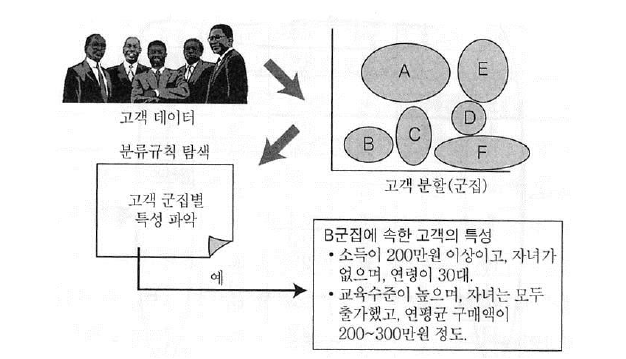
4. 군집화(Clustering)¶
- 정의
- 레코드들을 유사한 특성을 지닌 몇 개의 소그룹으로 분할하는 작업
- 군집화의 활용
- 다른 데이터 마이닝 기법의 선행 작업으로써 많이 이용
- 분류 vs 군집화
- 분류 값의 유무
- 군집화 기법
- 계층적 군집분석
- 비계층적 군집분석: K-means, EM Algorithm, SOM(Self-Organizing Map)
데이터 분할(Data Partitioning)¶
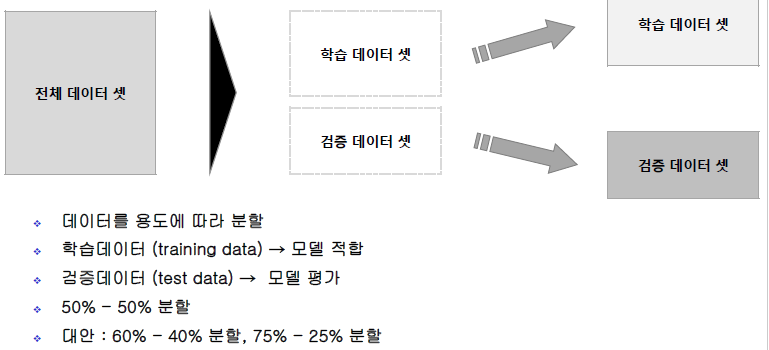
5 Folder Cross Validation¶
| 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|
| A | B | C | D | E |
- ABCD : 학습 , E : 검증
- BCDE : 학습 , A : 검증
와 같은 방법으로 5가지의 경우의 수를 모두 입력 Data Mining Demo¶
1. Business Understanding¶
한 은행이 새로운 개인연금상품(PEP)을 신설하여 기존 고객들을 대상으로 가능한 많은 계좌를 유치하고자 한다.
고객의금융상품(PEP: Personal Equity Plan, 연금보험) 구매여부 예측에 의한 신규고객 창출
- 고객 프로파일 개발
- 다이렉트 메일 광고 효율성 제고
- 타겟 메일링에 의한 응답률 제고
분석 절차
- 1) 기존 고객 DB로부터 시험 메일 발송을 위한 표본 고객 목록을 추출
- 2) 새로운금융상품(PEP)의 제안 메일을 발송
- 3) 고객의 반응을 기록
- 4) R을 이용하여 캠페인 결과를 분석
2. Data Understanding¶
학습용 데이터 300건 (pepTrainSet.csv)
검증용 데이터 200건 (pepTestSet.csv)
신규 고객 데이터 200건 (pepNewCustomers.csv)
3. Data Preparation¶
In [1]:
train <- read.csv("pepTrainSet.csv", stringsAsFactors=F)
train <- subset(train, select=-c(id))
test <- read.csv("pepTestSet.csv", stringsAsFactors=F)
newd <- read.csv("pepNewCustomers.csv", stringsAsFactors=F)
train$pep <- factor(train$pep)
test$pep <- factor(test$pep)
str(train)
4. Modeling(Cont.)¶
In [5]:
install.packages("caret",repos = "http://cran.us.r-project.org") #데이너 전처리 / 모델
install.packages("ROCR",repos = "http://cran.us.r-project.org") # 모형의 그래프 생성과 평가
install.packages("C50",repos = "http://cran.us.r-project.org") # 분류 분석, 의사결정나무 (Decision Tree)
In [2]:
library(caret)
library(ROCR)
library(C50)
In [8]:
?C5.0Control
first candidate model : Decision Tree(C5.0)¶
In [3]:
c5_options <- C5.0Control(winnow = FALSE, noGlobalPruning = FALSE)
c5_model <- C5.0(pep ~ ., data=train, control=c5_options, rules=FALSE)
summary(c5_model)
In [5]:
## plot(c5_model, cex=1.0)
# 결과가 그림으로 찌그러져 나온다.
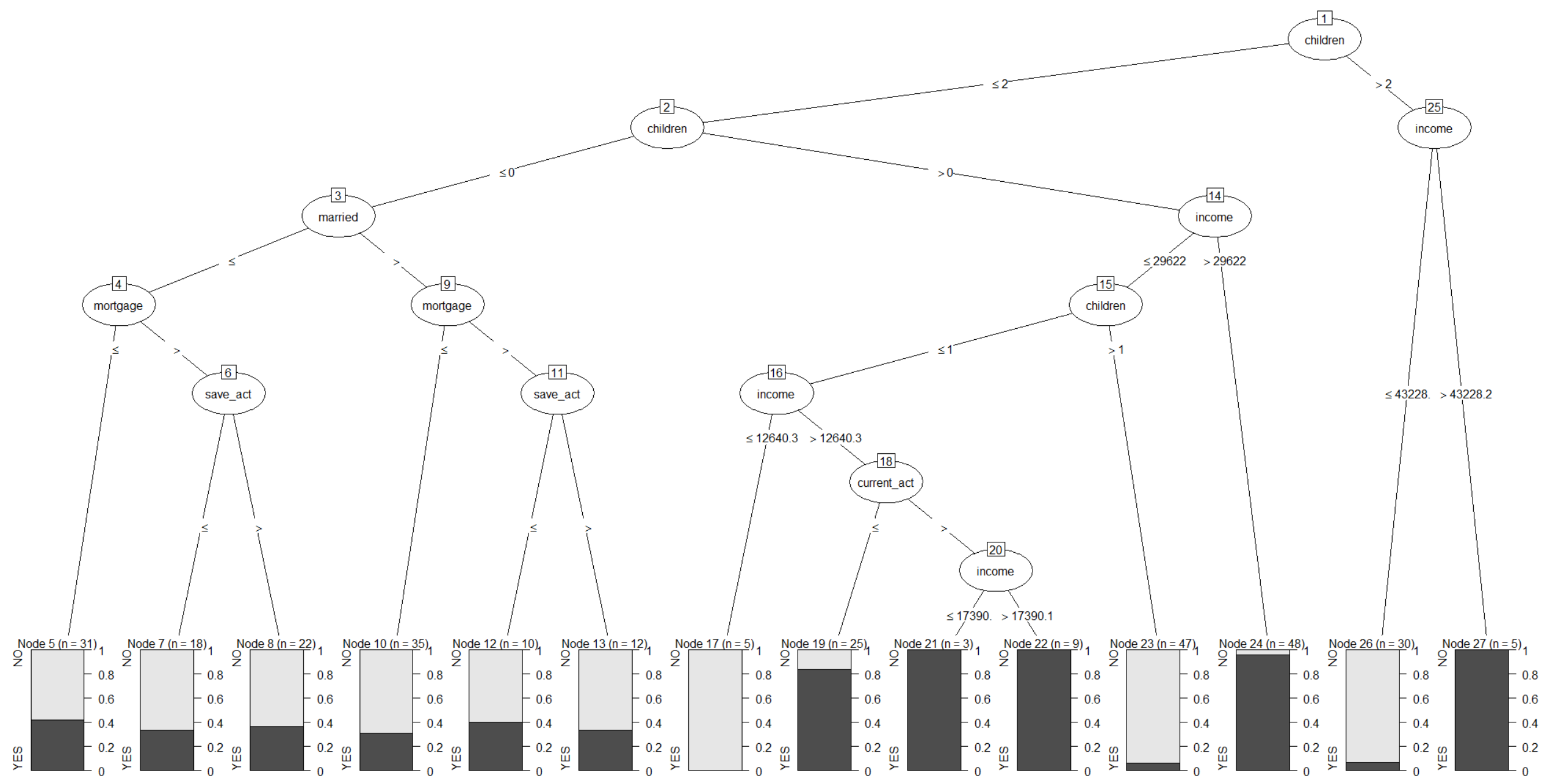
In [7]:
plot(c5_model, cex=1.0)

Second candidate model : Logistic Regression¶
In [10]:
lm_model <- glm(pep~.,data=train,family=binomial)
summary(lm_model)
Model evaluation by Confusion Matrix¶
In [11]:
install.packages("e1071",repos = "http://cran.us.r-project.org")
In [12]:
library(e1071)
In [14]:
test$c5_pred <- predict(c5_model, test, type="class")
test$c5_pred_prob <- predict(c5_model, test, type="prob")
head(test)
str(test)
In [17]:
confusionMatrix(test$c5_pred, test$pep) # .No, .Yes생성하는
#pred.prob.No -> NO 의 확률
#pred.prob.Yes -> Yes의 확률
In [19]:
test$lm_pred <- ifelse(predict(lm_model, test, type="response") > 0.5, "YES", "NO")
test$lm_pred_prob <- predict(lm_model, test, type="response")
confusionMatrix(test$lm_pred, test$pep)
In [22]:
options(repr.plot.width = 5, repr.plot.height=5)
c5_pred <- prediction(test$c5_pred_prob[, "YES"], test$pep)
c5_model.perf <- performance(c5_pred, "tpr", "fpr")
lm_pred <- prediction(test$lm_pred_prob, test$pep)
lm_model.perf <- performance(lm_pred, "tpr", "fpr")
plot(c5_model.perf, col="red")
plot(lm_model.perf, col="blue", add=T)
legend(0.7, 0.7, c("C5","LM"), cex=0.9, col=c("red", "blue"), lty=1)

- 그래프가 경사가 더 크고 급격하게 상승 후 마지막 정확도가 동일 한 경우
- 동일 한 정확도를 가지고 있더라도 선택하는 Subset 즉, Choosing을 하게 될 사람 수가 적게 된다면
위의 빨깐 선보다 경사가 높은 경우를 선택하는 것이 좋다.
- 동일 한 정확도를 가지고 있더라도 선택하는 Subset 즉, Choosing을 하게 될 사람 수가 적게 된다면
Deployment¶
In [27]:
newd$c5_pred <- predict(c5_model, newd, type="class")
newd$c5_pred_prob <- predict(c5_model, newd, type="prob")
target <- subset(newd, c5_pred=="YES" & c5_pred_prob[ ,"YES"] > 0.8)
head(target[order(target$c5_pred_prob[,"YES"], decreasing=T),])
# write.csv(target[order(target$c5_pred_prob[,"YES"], decreasing=T), ], "dm_target.csv", row.names=FALSE)